Compute
Chalk Compute
Run containers, agents, and inference workloads on managed or self-hosted infrastructure.
Overview
Chalk Compute is a container runtime for running arbitrary workloads — AI agents, model inference, data pipelines, or any long-running process — in isolated, sandboxed environments. Workloads can run on Chalk’s managed serverless fleet or on your own EKS/GKE clusters.
To use Compute on a cluster, follow the Compute Setup guide.
Then install the SDK to get started:
pip install chalkcomputeCompute fits into the broader Chalk platform alongside the Context Engine and MCP Gateway. Your application talks to the platform from outside the VPC; all workload code, data sources, and credentials stay inside it.
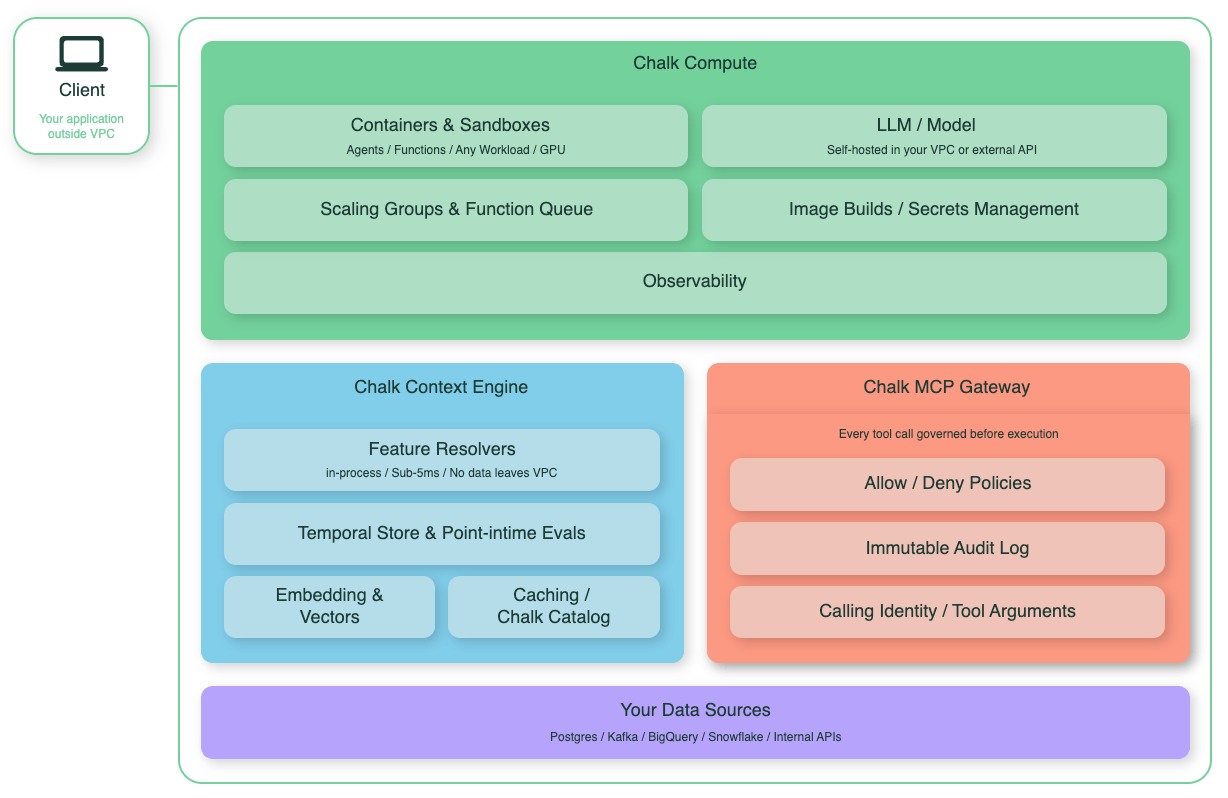
Core components
Sandboxes
Every workload runs in a gVisor-isolated sandbox with its own filesystem, network namespace, and resource limits. Sandboxes support CPU and GPU workloads, enforce multi-tenant isolation at the kernel level, and can be deployed on managed infrastructure or self-hosted Kubernetes.
from chalkcompute import Container, Image
c = Container(image=Image.debian_slim(), cpu="2", memory="4Gi").run()
result = c.exec("python", "-c", "print('hello from a sandbox')")
print(result.stdout_text)
c.stop()Containers
Containers wrap a sandbox with image building, file
upload, secret injection, and an exec-style invocation API. Use a container
for one-off batch jobs, interactive sessions, or long-running processes that
don’t need replication.
from chalkcompute import Container, Image
c = Container(
image=Image.debian_slim("3.12").pip_install(["requests"]),
name="hello-container",
cpu="1",
memory="2Gi",
).run()
result = c.exec("python", "-c", "print('hello from a container')")
print(result.stdout_text)
c.stop()Scaling Groups
Scaling Groups deploy a replicated, HTTP-fronted service with autoscaling and an automatically provisioned DNS name. Use them for inference servers, internal APIs, agent backends, and any long-lived service that needs to be reachable from outside the cluster.
from chalkcompute import ScalingGroup, Image
sg = ScalingGroup(
image=Image.debian_slim("3.12").pip_install(["flask"]),
name="hello-api",
port=8080,
min_replicas=1,
max_replicas=3,
).deploy().wait_ready()
resp = sg.call("/health", method="GET")
print(resp.status_code, resp.text)
sg.delete()Images
Images define the software environment for a sandbox. The Image
API provides a fluent builder for installing pip packages, system dependencies, and local
files. Images are content-addressed — identical specs share a cached build, and incremental
changes only rebuild affected layers.
img = (
Image.debian_slim("3.12")
.pip_install(["torch", "transformers"])
.run_commands(
"apt-get update",
"apt-get install -y ffmpeg",
)
)Volumes
Volumes provide persistent, versioned file storage backed by object storage. A Rust-based FUSE driver mounts volumes directly into containers as normal directories. Writes use batch copy-on-write semantics — changes are buffered locally and flushed on sync, giving other consumers a consistent view. Past versions are retained, enabling fork semantics for parallel agent workloads.
from chalkcompute import Container, Image, Volume
vol = Volume("training-data")
vol.put_file("inputs/example.txt", b"hello from a volume\n")
c = (
Container(image=Image.debian_slim("3.12"), name="volume-demo")
.mount_volume("training-data", "/data")
.run()
)
result = c.exec("python3", "-c", "print(open('/data/inputs/example.txt').read())")
print(result.stdout_text)
c.stop()
Functions
Functions let you deploy a Python callable as a remotely invocable endpoint. Chalk handles image building, scaling, and routing — you write a function, deploy it, and call it from anywhere.
import chalkcompute
@chalkcompute.function(cpu="1", memory="1Gi")
def normalize_name(name: str) -> str:
return " ".join(part.capitalize() for part in name.split())
normalize_name.wait_ready()
print(normalize_name("ada lovelace")) # Ada LovelaceSecrets
Inject secrets into sandboxes, containers, and functions via the Secret API.
Secrets are resolved at deploy time and exposed to the workload as environment
variables. The four factory constructors cover the common cases:
Secret.from_env(name)— read from Chalk’s managed secret store by name.Secret.from_integration(name)— expose the credentials of a named Chalk integration (e.g."prod_postgres") as standard env vars.Secret.from_local_env(name, env_var_name=...)— forward a secret from the local environment at deploy time (handy for dev loops).Secret.from_local_env_file(path)— forward every entry in a local.envfile.
import os
from urllib.parse import urlparse
import chalkcompute
from chalkcompute import Secret
@chalkcompute.function(
secrets=[
Secret.from_env("OPENAI_API_KEY"),
Secret.from_integration("prod_postgres"),
],
)
def call_api(prompt: str) -> str:
openai_api_key = os.environ["OPENAI_API_KEY"]
database_url = os.environ["DATABASE_URL"]
headers = {"Authorization": f"Bearer {openai_api_key}"}
db_host = urlparse(database_url).hostname
# Pass headers to your OpenAI-compatible client and database_url to
# your Postgres client.
return f"ready to call OpenAI for {prompt!r} and log to {db_host}"
Security
The Security section of the Sandbox doc covers the identity and networking controls available for production workloads: workload identity federation (OIDC-compliant per-sandbox credentials), the MCP Gateway for proxying tool-use APIs without exposing real credentials, network policies for restricting egress, and WireGuard tunnels for private connectivity between workloads.
Choosing the right primitive
Every workload is one of three shapes. The framework below helps you choose:
| Mental Model | Reach For | Example |
|---|---|---|
| An ephemeral task | Container | Run an agent’s generated code, a one-off data backfill, or a per-session agent workspace that is torn down when the session ends |
| An application that lives forever | ScalingGroup | A vLLM inference server, an internal API, a persistent agent or chat backend, or a hosted MCP server |
| A (potentially long) RPC call | Function | An embedding or re-ranking endpoint, an enrichment call inside a resolver, or a “score this transaction” call that returns a float to the query server |
A Sandbox and a
Container are the same execution primitive —
both are ephemeral tasks — and differ only in the security policy applied to
them. Reach for a container by default. For a single long-running process you
don’t need to replicate, give the container a port rather than standing up a
scaling group.
The diagram below shows how these primitives sit inside a Chalk-managed deployment in your cloud account. Containers and scaling groups run on a gVisor-hardened nodepool; image builds, the function registry, secrets, and volumes are all reachable from the same VPC; clients can hit the API Server directly, the Envoy router for HTTP traffic into a scaling group, or the Function Queue for async invocations.
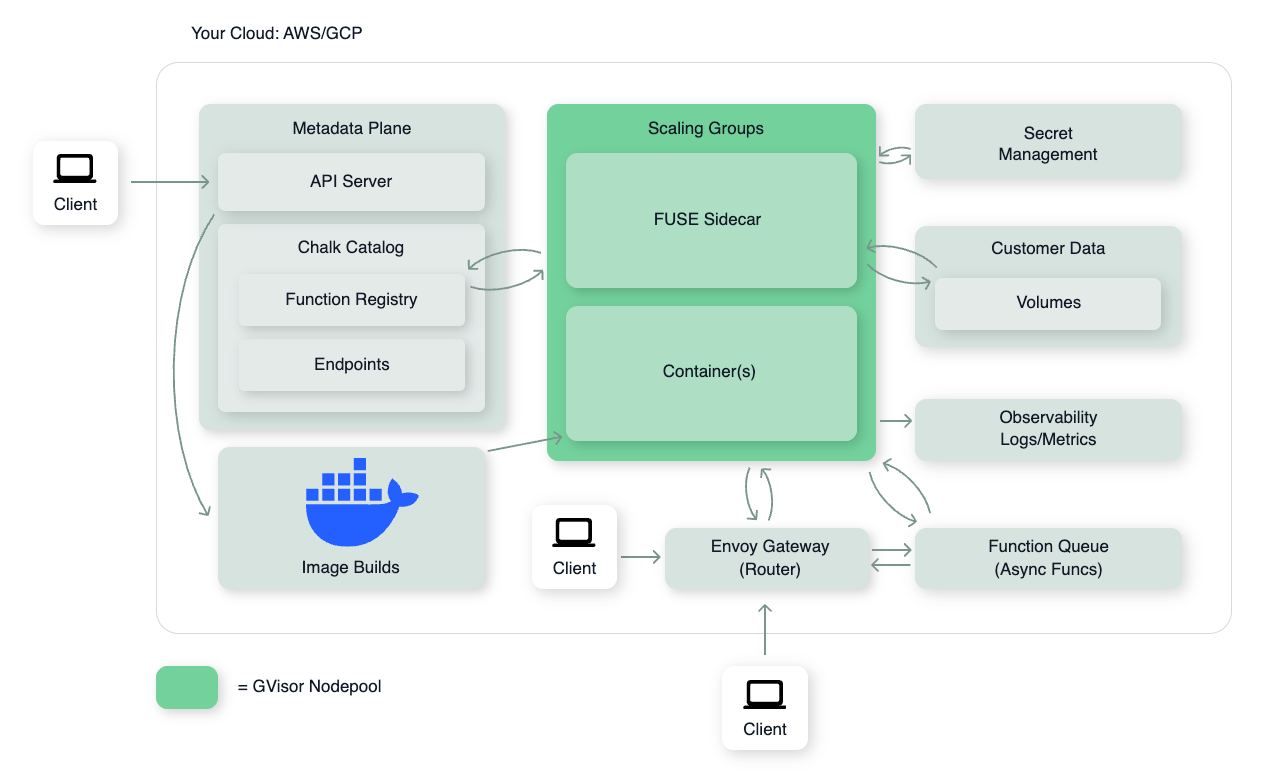
These three primitives compose with two supporting layers.
Filesystem
Define the software environment and the persistent storage available to a workload. Always used together with one of the primitives above, never on their own.
| Use case | Use |
|---|---|
| Define the software environment baked into a workload (pip packages, system deps, local files) | Image |
| Persistent, versioned, copy-on-write storage shared across workloads or runs | Volume |
Chalk Catalog
Functions deploy a Python callable onto a Scaling Group and register it in
the Chalk Catalog. Once registered, the callable is reachable from the rest
of Chalk — call it from Chalk SQL, from a resolver, from the query server, or
from a DataFrame via F.catalog_call(). Functions also pick up runtime
features that the underlying Scaling Group does not provide on its own: async
invocation, streaming results, nested calls, automatic retries, concurrency
caps, rate limits, and request-queue-driven autoscaling.
Reach for a Function when the workload needs to participate in the feature engine, or when you want those runtime controls without wiring them yourself on a Scaling Group.
| Use case | Use |
|---|---|
| Python callable reachable from Chalk SQL, resolvers, the query server, or a DataFrame | Function |
| Async / streaming / nested calls with batching, retries, concurrency, or rate-limit controls | Function |