- Introduction
- Platform Architecture
Introduction
Platform Architecture
How it all fits together.
Chalk’s platform is architected to
- retrieve fresh features across heterogeneous sources with the minimum possible latency
- orchestrate and execute complex transformations on structured and unstructured data
- support online serving, offline training-set generation, and streaming ingestion in a single system
- uphold enterprise-grade guarantees for security, observability, and reliability
In short, Chalk was built to get the right data from the right place at the right time.
Online serving architecture
Let’s examine how the pieces work together to compute and serve features.
Suppose that you want to compute a set of features for making a decision about a request from a user:
- Your application sends an HTTP request to Chalk’s serving API for features
- Chalk’s query planner generates an optimized execution plan by analyzing feature dependencies and available data sources.
- Chalk’s compute engine
- retrieves fresh values from underlying sources with Resolvers
- pulls from Chalk’s low-latency online storage e.g. materialized features or cached features
- executes the generated query plan
- Returns computed features in response
- Newly computed feature values are stored and logged for reuse and auditability
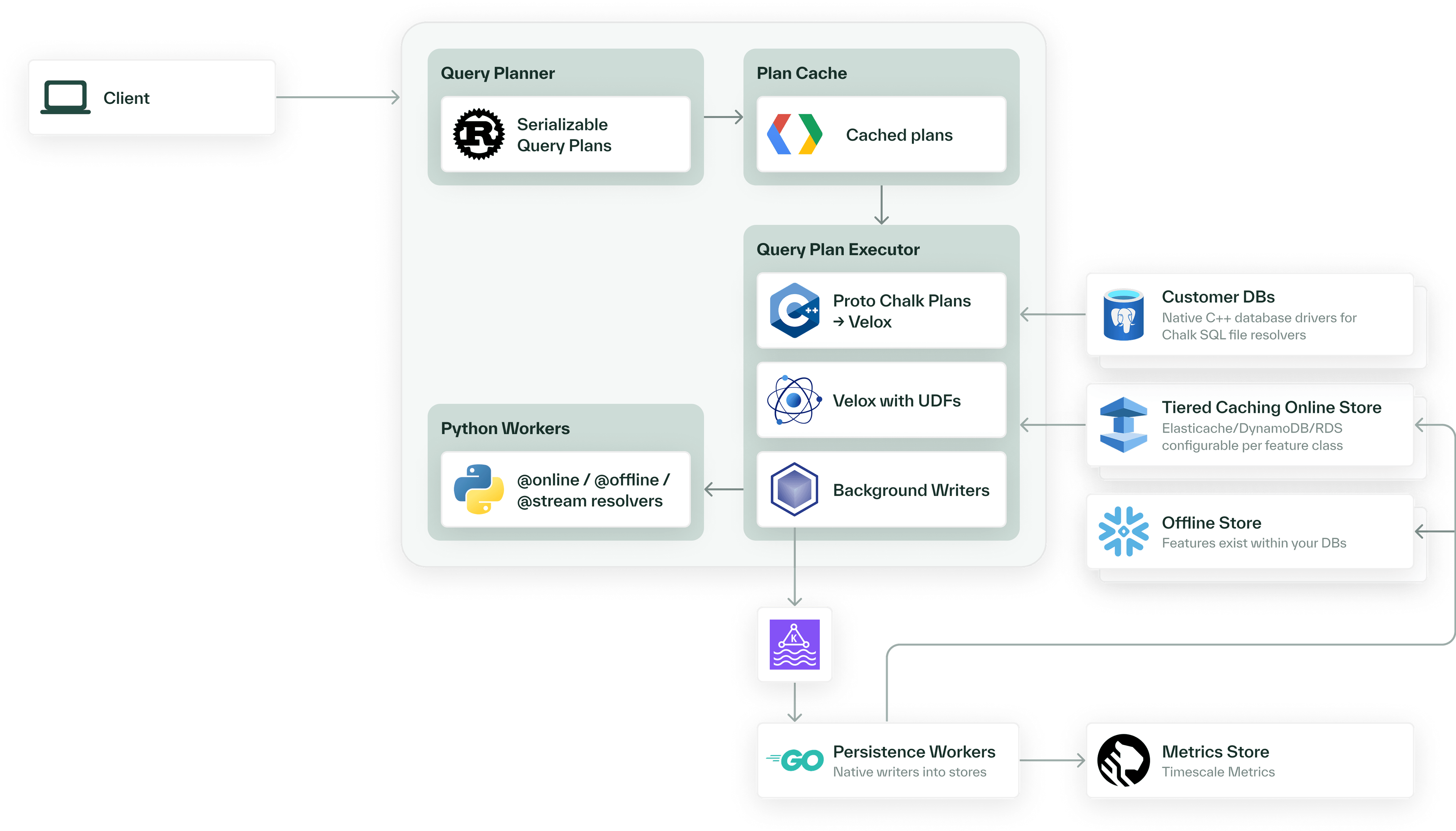
This entire online pipeline - from SQL queries and API calls to getting a response - runs in less than 5ms, even with heterogeneous data sources and complex logic. Chalk uses many techniques to reduce latency, such as:
- Automatic parallelism across pipeline stages
- Vectorization of pipeline stages that are written using scalar syntax
- Statistics-informed join planning
- Low-latency key/value stores (like Redis, BigTable, or DynamoDB)
- Transpilation of Python code into native code with Chalk’s symbolic Python interpreter
Data orchestration
Chalk eliminates the complexity of orchestrating data and ETL pipelines by building a dependency graph (DAG) of your features, which are defined using Python. At inference time, Chalk dynamically builds query plans (subgraphs of your feature DAG) without manual configuration, based on the features you request.
Write feature definitions in Python, and Chalk automatically
- Determines optimal computation and query planning strategies
- Handles caching, incremental updates, and backfills
- Provides built-in observability and data lineage without additional tooling
As a result, Chalk can serve as a drop-in replacement for orchestration tools like Dagster, Airflow, and Prefect while simultaneously providing purpose-built features for production ML workloads.
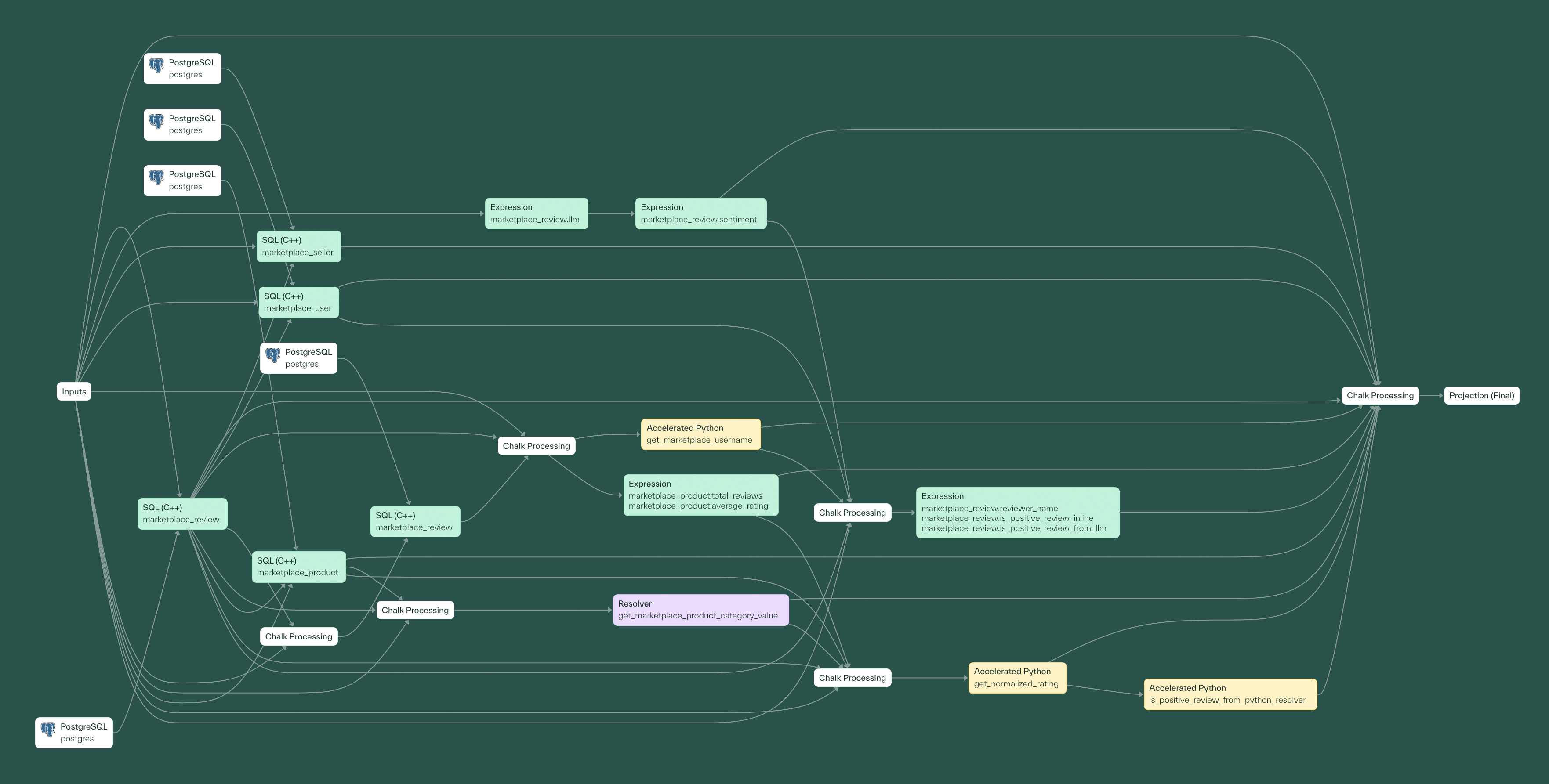
Declaratively defining features frees up data teams to focus on designing features instead of writing plumbing code. There’s no need to write custom glue code because Chalk interfaces directly with underlying data sources, managing all the connections and transformations behind the scenes.
Note: Features can also be computed on a recurring basis with scheduled queries or ingested continuously from streaming sources such as Kafka, Kinesis, and Pub/Sub.
Offline computation and serving
Chalk’s architecture also supports efficient point-in-time queries to construct model training sets or perform batch offline inference.
- Submit a training data request from a notebook client like Jupyter using Chalk’s Python SDK
- The query planner builds a point-in-time correct plan
- The compute engine pulls point-in-time correct feature values from offline storage
- Chalk returns a DataFrame of features to you.
Chalk integrates with your existing data providers (Snowflake, Delta Lake, or BigQuery) to ingest massive amounts of data from a variety of data sources and query it efficiently. Note that data ingested into the offline store can be trivially made available for use in an online querying context with Chalk’s Reverse ETL.
There’s an exhaustive list of supported ingestion sources in the Integrations section.
Data persistence and storage
Chalk uses different storage technologies to support online and offline use cases.
The online store is optimized for serving the latest version of any given feature for any given entity with the minimum possible latency. Chalk can be configured to use Redis or Memorystore for smaller resident data sets with strict latency requirements, or DynamoDB when horizontal scalability is required.
The offline store is optimized for storing all historical feature values, serving point-in-time correct queries, and tracking provenance of features. Chalk supports a variety of storage backends depending on data scale and latency requirements. Typically, Chalk uses Snowflake, Delta Lake, BigQuery, Iceberg, or Athena.
High-performance execution engine
Under the hood, Chalk uses Velox, an open source unified execution engine, to deliver high-throughput feature computation. We maintain a fork that’s been optimized for low-latency online inference.
You can think of Velox as a backend for query engines like Presto (AWS Athena) and Spark i.e. you can’t point Velox at a database and pass in a SQL expression. Rather than forcing users to work directly with low-level execution primitives, Chalk provides an ergonomic interface (Chalk Python SDK) for defining features, transformations, and pipelines.
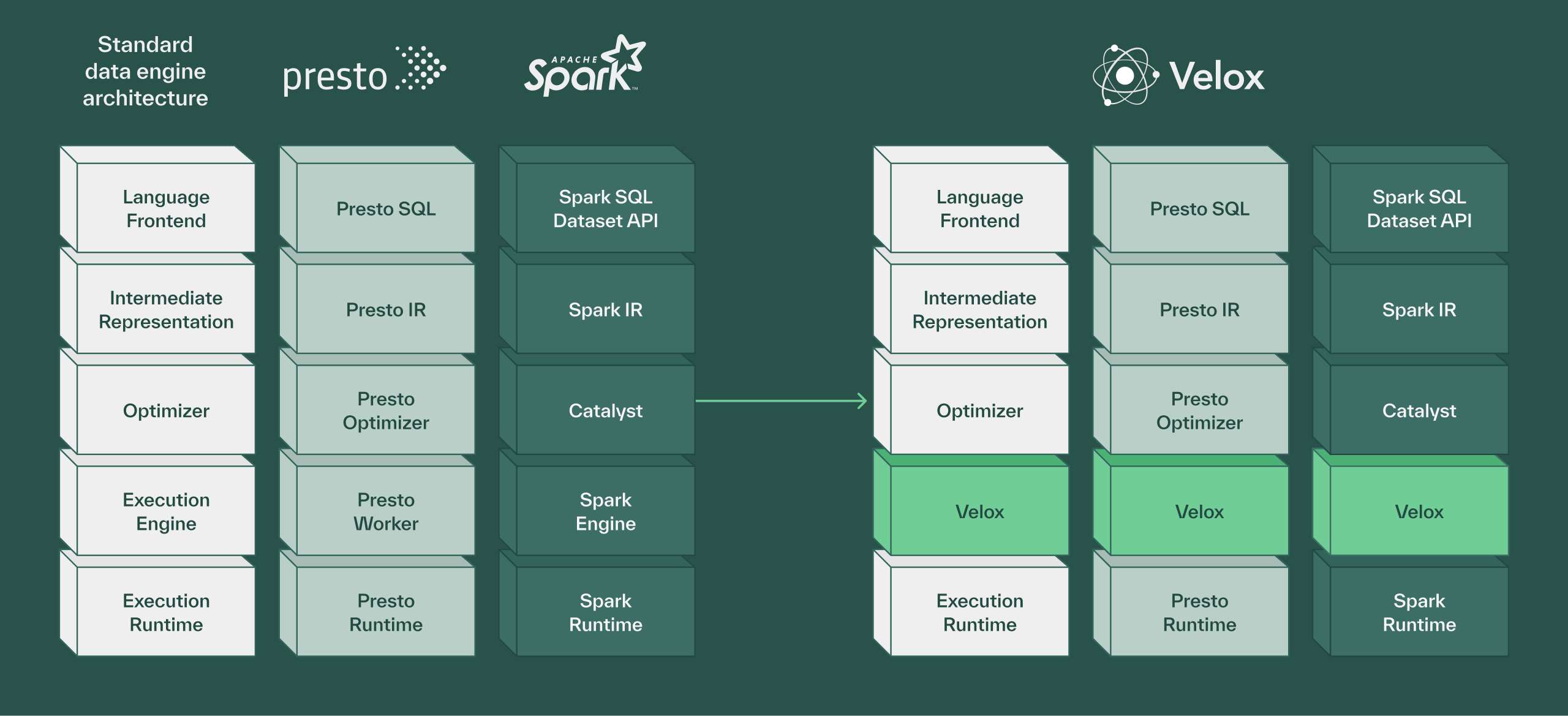
This architecture allows us to expose the power of vectorized computation with clean APIs that feel natural (like writing Pandas and Polars) to data scientists and engineers. Users write simple Python decorators and SQL queries, while Velox handles the complex optimizations that make these computations blazingly fast.
- Velox’s columnar memory layout and vectorized expression evaluation deliver significant performance improvements, with benchmarks showing 6-7x speedups on real analytical workloads
- Native support for structs, maps, arrays, and nested data types makes it ideal for feature engineering workflows
- Features like filter reordering, dynamic filter pushdown, and adaptive column prefetching optimize query execution based on runtime statistics
Service architecture
We offer both a hosted model (“Chalk Cloud”) and a customer-hosted model (“Customer Cloud”).
Most companies choose to run Chalk in their own cloud (VPC) for data residency and compliance. Chalk is traditionally deployed as a Platform As a Service into an isolated account under the management of the customer, with the core components (VPC, Kubernetes Cluster, Message Queues, etc) managed by Chalk.
Compute nodes run on Kubernetes (typically EKS on AWS, GKE on GCP, and AKS on Azure). If you have custom needs, we are happy to customize the deployment to fit with your service architecture.



- 1Creating secrets:The API server can be configured to have write-only access to the secret store.
- 2Reading secrets:Secret access can be restricted entirely to the data plane.
- 3Online store:Chalk supports several online feature stores, which are used for caching feature values. On AWS, Chalk supports DynamoDB and Elasticache.
Metadata Plane
The Metadata Plane is responsible for storing and serving non-customer data (like alert and RBAC configurations). It can control many Data Planes, which it manages through the Kubernetes API, enabling tasks such as scaling deployments and running batch jobs.
In short, the Metadata Plane handles:
- Deployment orchestration
- Access control
- Monitoring and alerting
- Feature discovery
It does not have access to customer data.
Data Plane
The Data Plane encompasses the execution environment for feature pipelines along with the storage and serving infrastructure for both online and offline feature stores.
A single Data Plane can run many Chalk Environments.
Often, companies will have 2-3 environments (like qa, stage, and prod.)
If running in a single data plane, these environments share resources, which helps with cost and ease of setup.
However, if you prefer to have stronger isolation between Chalk Environments, each Chalk Environment can run in a separate Data Plane. You would typically share one Metadata Plane to orchestrate all Data Planes, and deploy the shared Metadata Plane to the most sensitive of the environments.
Deployment Models
Chalk offers several deployment options to provide the right level of infrastructure control.
Chalk-Hosted Deployment
In the Chalk-Hosted Deployment, both the Metadata Plane and Data Plane run in Chalk’s cloud account. Deployed in this manner, Chalk runs as a SaaS application. There is no infrastructure to manage, and no ability to see inside the cloud account running Chalk.
Customer Cloud Deployment
Most customers choose our Customer Cloud Deployment. In this model, the customer runs the Data Plane in their own cloud, while Chalk runs the Metadata Plane in Chalk’s managed cloud environment.
This deployment model strikes a good balance between security and ease of maintenance. No one at Chalk will be able to access your data, but the Chalk team can handle upgrades to the underlying resources without your team’s involvement.
Air-Gapped Deployment
Chalk offers the option to self-host both the Data Plane and Metadata Plane. In the Customer Cloud Deployment, only the Data Plane runs in your cloud account, whereas in the Air-Gapped Deployment, the Metadata Plane joins the Data Plane in your cloud account.
There are two primary reasons that customers will choose to host the Metadata Plane:
- Regulatory requirements: highly regulated environments (like FedRAMP) may require additional security control.
- Disaster recovery: deploying both the Metadata Plane and Data Plane into your cloud account means that Chalk will continue to run independent of any Chalk uptime.
In this configuration, no service hosted by Chalk needs to talk to your instance. Telemetry can be exported for billing purposes (over topics), but is non-essential to uptime of your instance. In the event of a complete outage in Chalk’s cloud accounts, your instance service would continue running indefinitely without disruption.
Data Plane Architecture
Chalk has a few tiers of concepts within the Data Plane that are important to understand when thinking about how to structure your deployment, such as how many environments you should set up. Each customer is associated with a team. Each team is tied to one or more projects, and each project can have one or more environments. The team, project, and environment concepts are all logical groupings for the underlying Kubernetes resources of Data Plane components.
Each environment deploys into its corresponding Kubernetes namespace. An environment has at least one resource group, which is one set of Data Plane components, as well as a metrics database deployment. Several environments can be deployed to the same Kubernetes cluster.
Every Chalk-managed Kubernetes cluster has a set of background processes that can be shared across environments deployed to that cluster. These background processes include load balancers, background persistence workers, a Clickhouse deployment for tracing, and a cluster manager.
Most customers have a team, a project, and one or more environments deployed across one or more Kubernetes clusters, however the exact structure of your deployment is flexible within the constraints outlined in the previous paragraph.
Monitoring
Native integrations with PagerDuty and Slack ensure teams are immediately alerted to any issues in their feature pipelines.
Beyond alerting, every Chalk query is fully instrumented with traces and detailed logs, enabling both broad system-wide monitoring and deep request-level debugging across every stage of computation—down to the root data source. With Chalk, data teams get
- Comprehensive logging & debugging
- Resolver execution details
- Feature computations
- Cache misses
- Data source failures
- Feature staleness
- Feature ownership tracking
- Metrics and performance monitoring
- Features: request volumes, computation times, and error rates
- Models: inference latency, prediction accuracy, and resource utilization
- System: query throughput, system latency, and pipeline health
- End-to-end request tracing
- Track the inputs and outputs of every step in any run
- Lineage tracking from data source to final predictions
Easily, build your own views and set up custom dashboards to visualize your metrics and configure smart alerts with custom formulas that notify you instantly when thresholds are crossed or anomalies are detected.
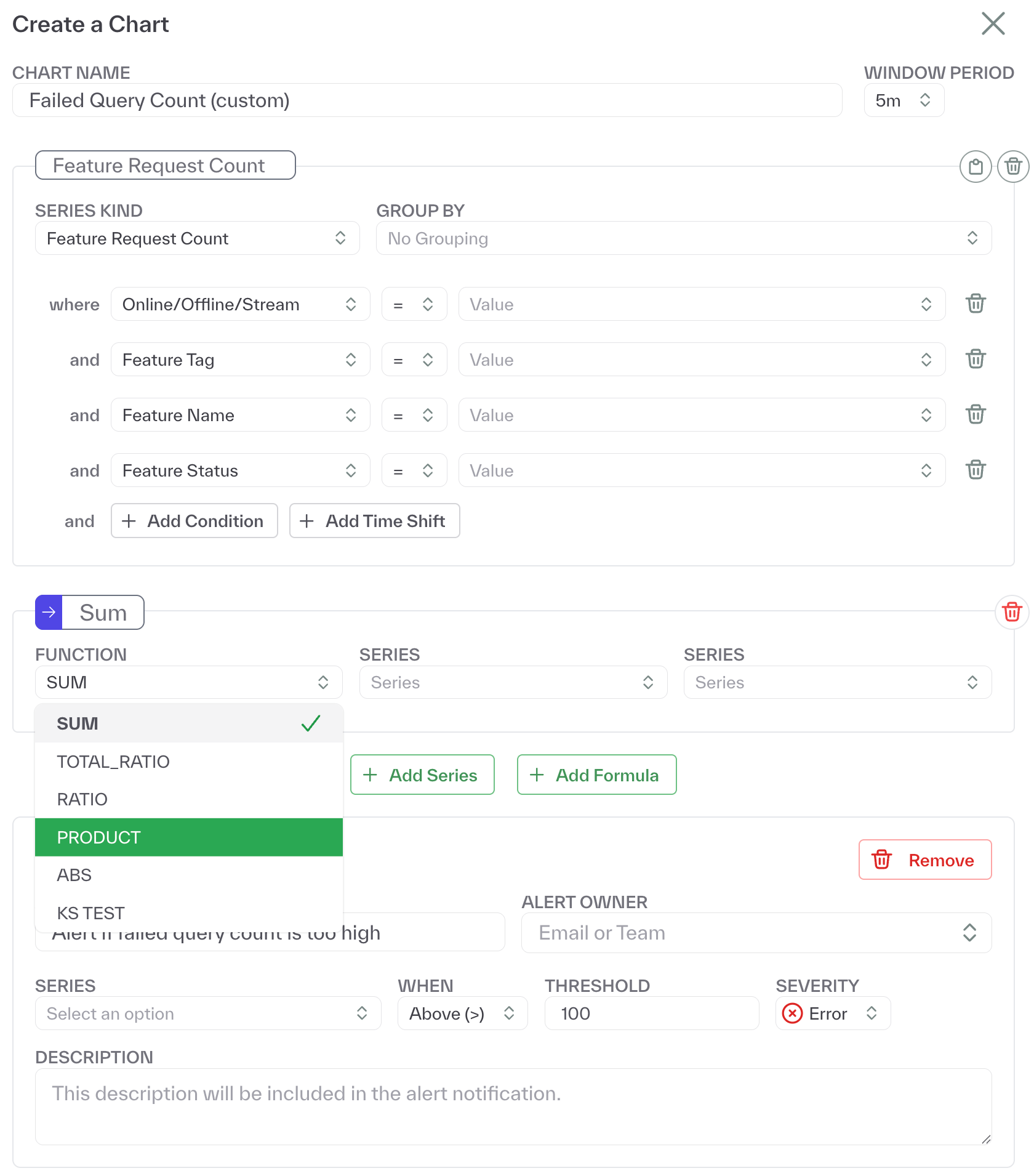
This flexibility to configure and define your own metrics makes it easy to answer common questions such as how often certain features are computed, how long individual computations take, and what the average value for a feature is.
Architecting maintainable and scalable systems for enterprise success
By both connecting to your data stores directly and computing features post-fetch, Chalk makes it trivial to integrate new data sources from other teams, dramatically increasing predictive accuracy and the context available to your models.
Your systems can also bidirectionally integrate with Chalk’s underlying infrastructure, which is built on widely-adopted technologies like Redis or DynamoDB, and leverages open standards like Arrow, Parquet, and Iceberg—ultimately maximizing compatibility and unlocking downstream analytical workflows
Together, these architectural choices enable enterprises to build future-proof ML and AI systems that scale with their needs, maintain interoperability, and seamlessly integrate with their existing technology stack.