Changelog
Updates to Chalk!
March 27, 2026
Parse Expressions for Stream Resolvers
We now show you the compiled C++ expression actively running for stream resolvers in the resolver page in the feature catalog under “Definition”, along with the original Python function.
Online Query Reruns
Online queries can now be rerun using the button on the top right of the online query page. This will open the online data explorer and pre-fill the configuration and inputs from a specific query run. This functionality previously only existed for offline queries.
Offline Store Table Names
We now expose offline store table names, which are hashes of feature fqns (fully-qualified names) . Previously, if you wanted to build your own observability stack and integrate with Chalk’s offline store feature value table names, it was pretty difficult. These names were previously only exposed in the dashboard on the feature catalog page. Now, there are commands through Chalk clients and the Chalk CLI to expose this.
March 20, 2026
Team Scoped Access Tokens
Team-scoped access tokens authenticate to Chalk programmatically across various environments for infra-level actions that require broad team-level access.
Dark Mode in Dashboard
Dark Mode is now publicly available, because your features deserve to look good at 2 AM too. The toggle is available under your profile settings in the bottom left.
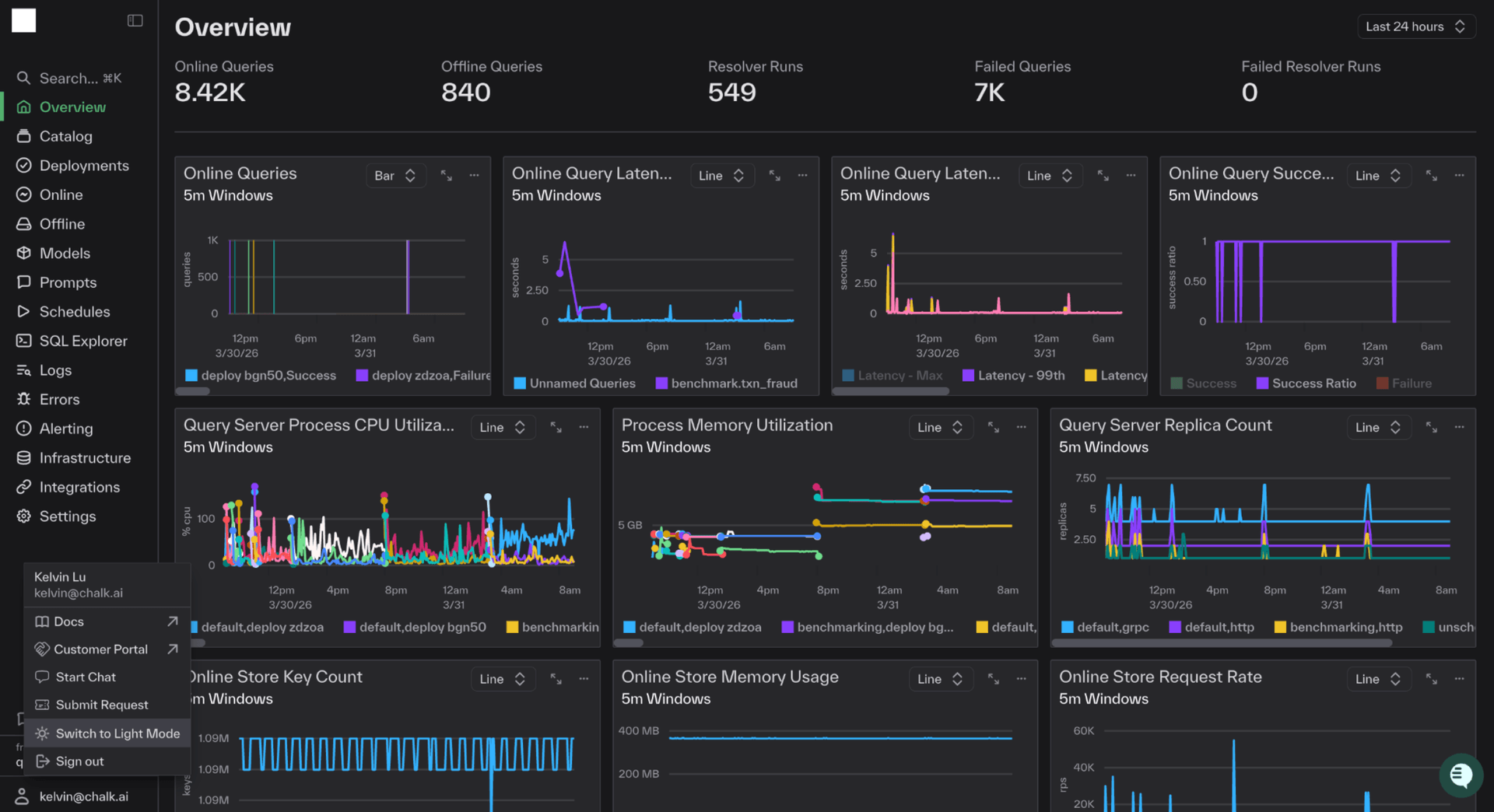
Resource Group Support for Streaming Resolvers
Resource group support is now available for streaming resolvers - allowing you to decide which set of compute/configs to run a resolver on. You can find Resource Groups under Infra > Resource Configurations on the left navbar of the web UI.
March 13, 2026
Access Logs
We now display all access logs under our “Logging” page. You can filter by Status Code, request path, and other properties. This page also overlays Kubernetes events on the access logs chart, which can help debug connectivity and uptime issues. Happy debugging!
Run Predictions against Vertex AI
We've added a new chalk.functions.vertex_predict function that allows you to run predictions against Vertex AI endpoints. Chalk will vectorize and run multi-row predictions in parallel on isolated pods, preventing resource contention. Read more here.
March 6, 2026
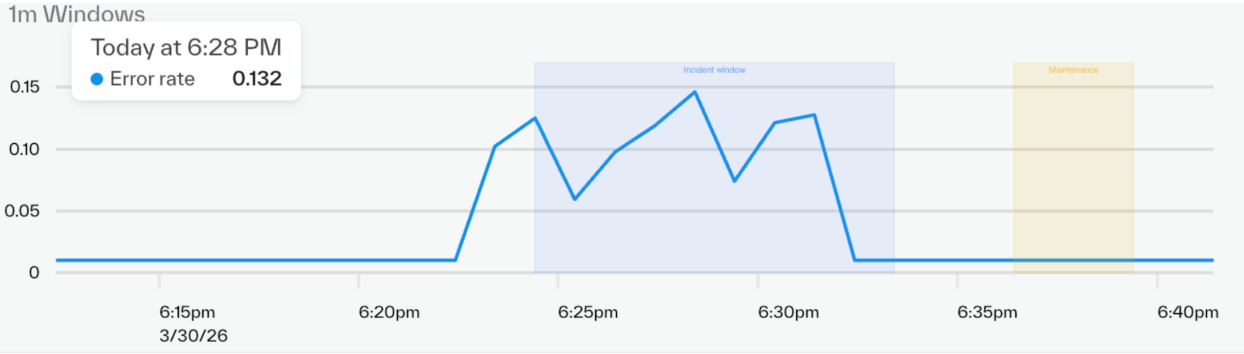
Chart Annotations
You can now annotate your charts - vertical lines for high signal activities, shaded boxes for times, and text annotations for communication.
March 2, 2026
Chalk Rust and C# Clients
We have officially launched our open source Rust and C# Chalk clients. You can now query for features natively in these languages.
Externally Managed Integration Secrets
By default, we require you to create secrets through the Chalk UI for their integrations. Now, you can link to secrets in your cloud secret manager to configure data source integrations, making it easy to manage secret rotation outside of Chalk.

Autospilling for Large Offline Queries
When an offline query processes more data than can fit in memory, the execution engine automatically spills intermediate results to local disk rather than failing with an out-of-memory error. This currently defaults to 60% of available memory and should prevent a lot of OOMing.
February 26, 2026
Materialized Aggregations - weighted approximate Top K
Chalk now supports a weighted version of approximate Top K as a materialized aggregation.
Instead of ranking values purely by frequency, you can rank them by weight, such as transaction amount.
This enables questions like:
- Which category accounted for the most revenue last month
- Which segment contributed the highest weighted score
The aggregation maintains constant memory usage and supports streaming updates.
PyTorch dataset integration
Offline query results can now be converted directly into PyTorch Dataset objects via the Python client.
This creates a direct path from feature computation to model training, eliminating custom data conversion steps in ML pipelines.
Trigger Perfetto profiling on demand
Perfetto profiling can now be triggered via HTTP instead of running continuously.
You can deploy the profiling daemon and use chalk profiling perfetto-snapshot to capture traces only when needed. This reduces storage overhead while improving debugging workflows for performance issues.
February 23, 2026
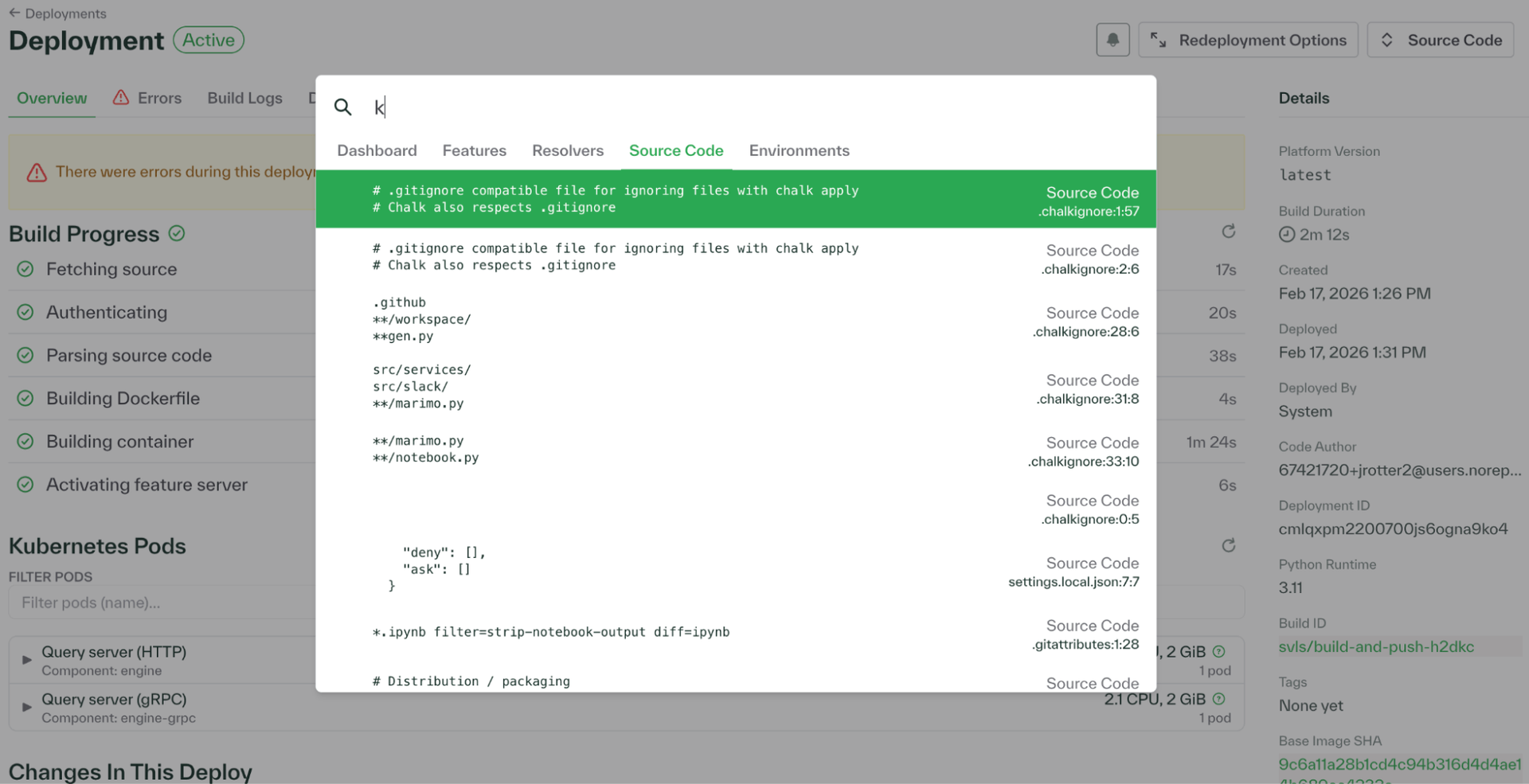
Search source code from anywhere
You can now search your deployment source code directly from the global command menu.
Press Command+K or pull up the search bar, select Source Code, and jump straight to matching resolvers or SQL definitions.
This significantly improves debugging workflows that require inspecting feature definitions or resolver logic.
Offline queries support numWorkers
The numWorkers parameter is now supported for offline queries when the Job Queue Manager is enabled.
This allows teams to rate-limit shard execution at the query level instead of modifying cluster-wide configuration. It improves predictability and resource control for large backfills and scheduled jobs.
Read more: https://docs.chalk.ai/docs/job-queue
Combined Aggs
We recently shipped an optimization to the Chalk query planner that combines aggregations in the query plan by default, which should dramatically improve performance especially for large offline queries computing multiple aggregations over high-cardinality datasets.
We have previously exposed this optimization through the environment variable CHALK_PLANNER_COMBINE_AGGREGATION_OPTIMIZATION as well as the planner option enable_combine_aggregation_optimization, but this is now defaulted to true in all platform versions v3.31.5 and onwards.
January 26, 2026
Faster Query Planning
Query planning is now even faster due to optimization work on the planner. Planning time improved by an average of 58%, reducing time-to-results and preventing online query timeouts for larger feature graphs.
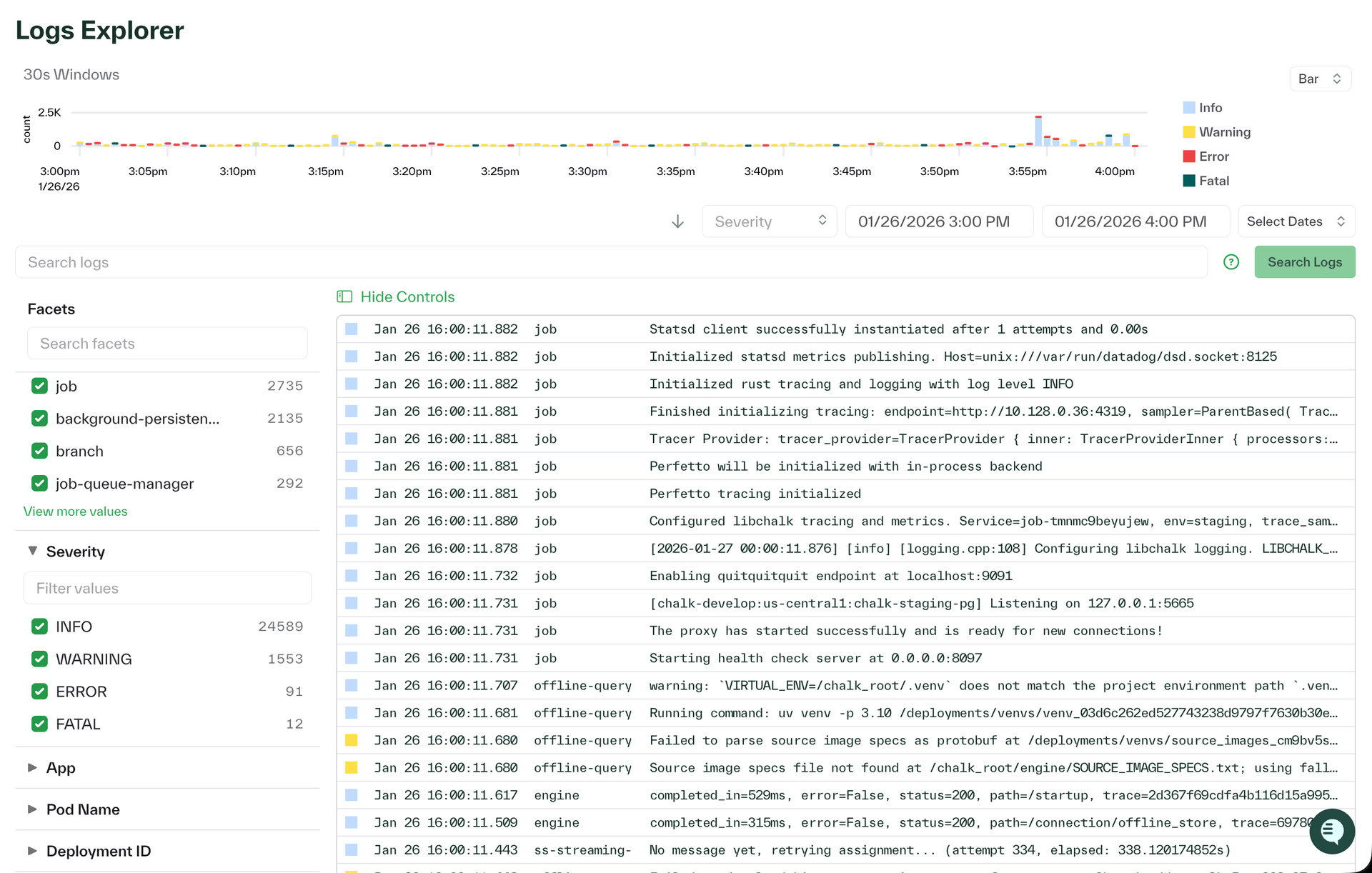
ClickHouse for logs and tracing
Logs and tracing now run on ClickHouse, improving search performance. Facets—indexed attributes like service, environment, status, region, and user_id—help narrow searches and surface the most common values for easier production debugging.
Enhanced query plan visualization
The query plan visualizer now supports node-by-node navigation through query DAGs. View associations between plan nodes and see how data flows through each query. Async batch UDFs and conditional nodes display in the data flow, making query plans easier to read and understand.
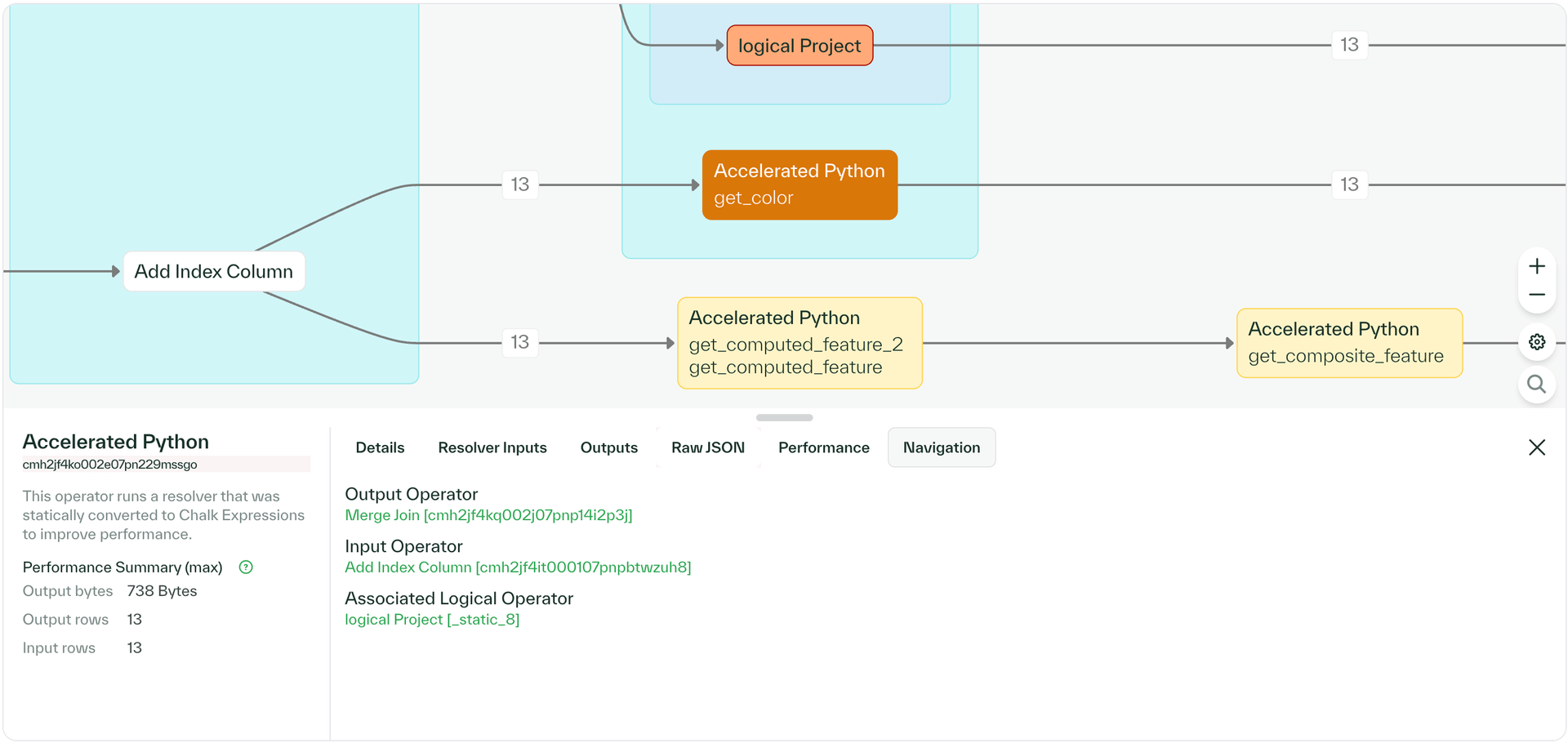
Store plan stages for scheduled queries
Scheduled queries now include a "Store plan stages" feature. This allows for improved query debugging.
December 22, 2025
Node monitoring improvements
The Nodes tab on the Kubernetes page in the dashboard now supports filtering and sorting by node type, node pool, and CPU utilization.
Expanded materialized aggregations
Although previously supported as windowed aggregations, approx_percentile aggregations are now supported as materialized aggregations as well. Teams can compute windowed percentile statistics efficiently, improving latency for percentile-based monitoring and modeling.
Native SQL driver for MS SQL
Chalk now provides a native drive for Microsoft SQL Server, enabling users to write SQL resolvers against their MS SQL data sources, and Chalk compiles and executes the queries using Rust and C++ for performance optimization. This expands Chalk's coverage across data ecosystems, allowing teams that store features or raw data in MS SQL to integrate directly without custom pipelines or data exports.
December 12, 2025
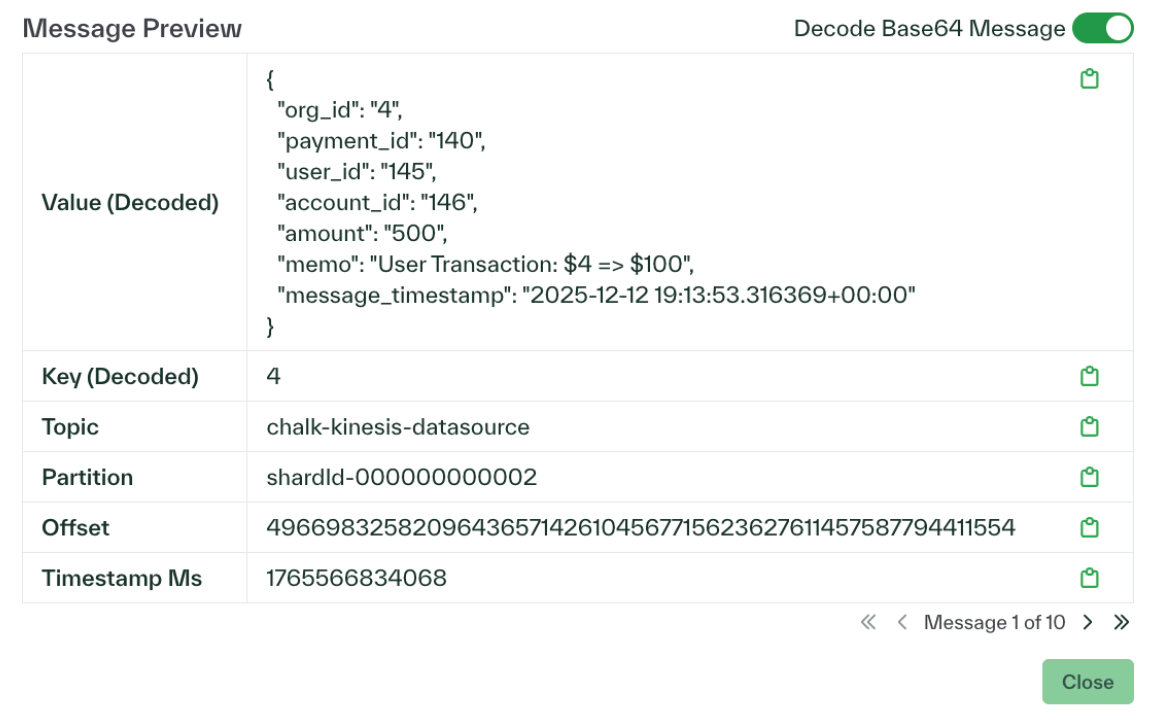
Preview messages when setting up stream sources
You can now preview sample messages while configuring a new stream source. This makes it easier to verify that data is flowing correctly and that message formats (like JSON) are being parsed as expected before saving the connection.
Updated navigation pane for faster workflows
We refreshed the left-hand navigation pane to make Chalk easier to move through. Related concepts are now grouped more clearly, visual noise has been reduced, and high-frequency actions are easier to access. The result is a more predictable, friction-free workflow, especially in larger projects.
November 25, 2025
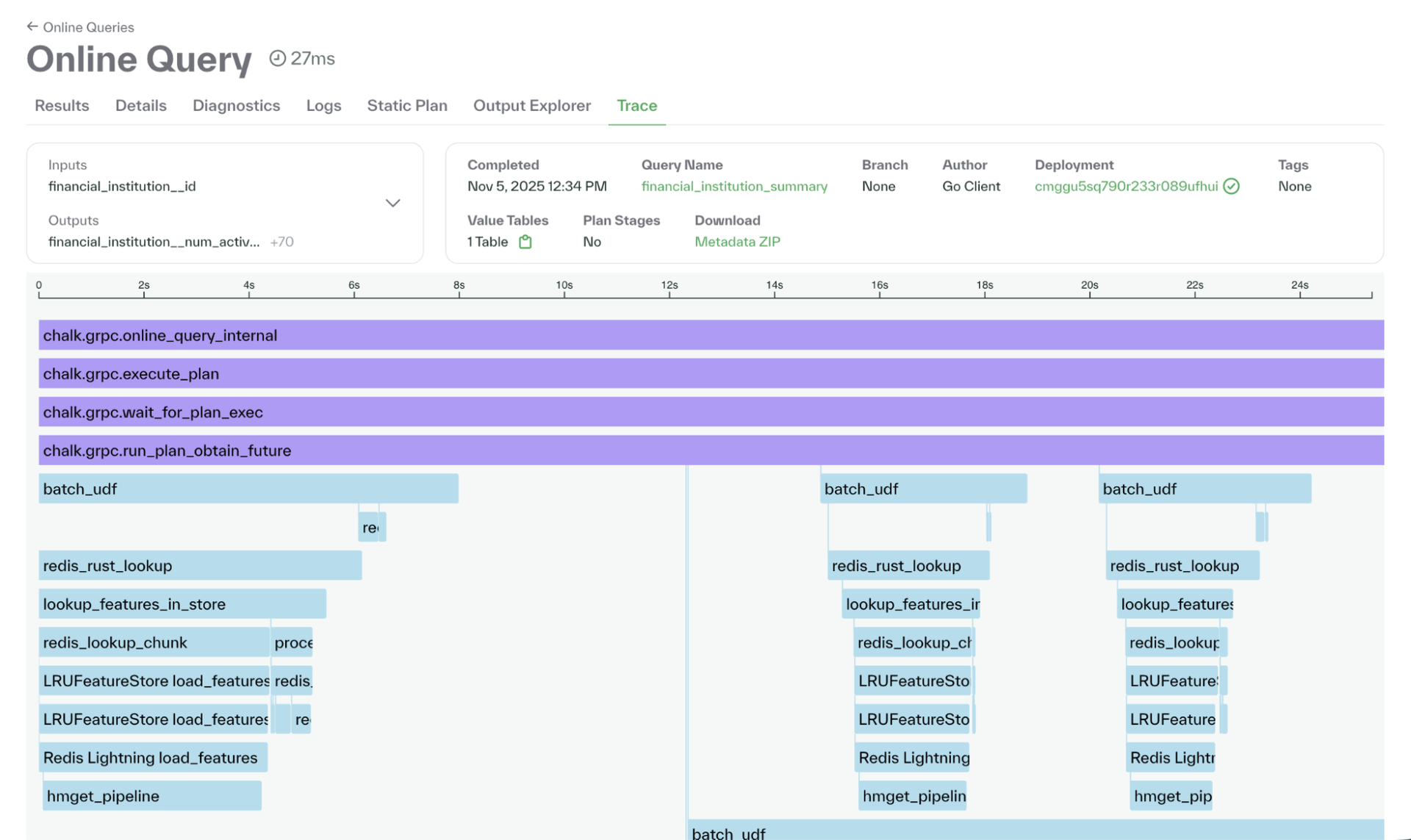
Tracing for query performance diagnosis
Tracing now provides full visibility into how queries execute inside Chalk.
Each resolver and model call is instrumented and timed, allowing teams to pinpoint slow spans, identify inefficient SQL, and understand query behavior end to end.
Trace data is surfaced directly in the dashboard, so engineers can drill into individual spans to view execution time, rows returned, and linked data source details.
Traces can be enabled per query using CLI, ChalkClient(), or configured to sample automatically in production for continuous monitoring.
October 27, 2025
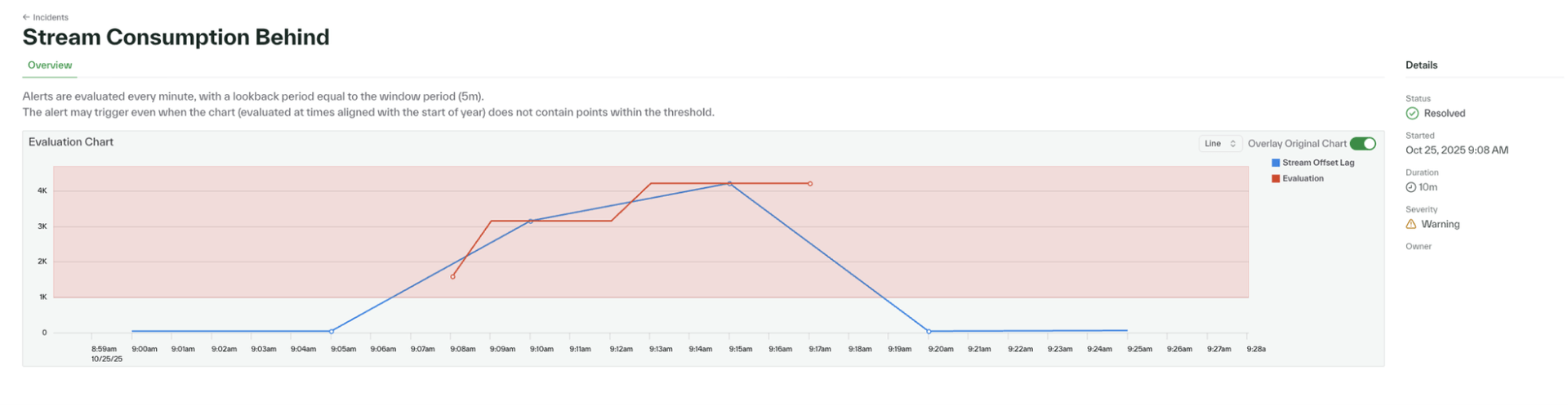
Stream consumption analytics
Stream incidents now record failure events at one-minute granularity, up from five minutes previously.
This provides finer visibility into where and when stream consumption fails, improving incident analysis and recovery time. Read more about Chalk’s metrics monitoring.
Method chaining for Chalk DataFrame
The Chalk DataFrame library now supports method chaining, allowing expressions like
tbl = pa.table(
{
"txns_last_hour": [[1, 2, 3, 4, 5], [100], [200, 201]],
"max_txns_allowed": [3, 5, 4],
}
)
df = DataFrame.from_arrow(tbl)
out = df.project(
{
"velocity_score": _.txns_last_hour
.cardinality()
.cast(float)
.least(_.max_txns_allowed + 0.5)
.ceil()
.cast(int),
"velocity_score_2": F.cast(
F.ceil(
F.least(
F.cast(F.cardinality(_.txns_last_hour), float),
_.max_txns_allowed + 0.5
)
),
int,
),
}
)The underscore interface is now the recommended API — it’s cleaner, type-safe, and validated by the Chalk function registry. Discover more about Chalk DataFrame aggregations and filters.
Cron query tracking
Scheduled (cron) queries now include detailed job-level status tracking, mirroring the system used for backfills.
Teams can now see when jobs start, skip, or fail — and identify the exact cause directly in the UI. Learn more about scheduling queries for automated runs.

Vector aggregates
Chalk now supports materialized vector aggregates such as sum and mean. These precomputed embeddings accelerate workloads involving vector math and high-dimensional similarity features.
Velox integration in Query Plan Viewer
The query plan viewer now links Velox physical execution data to individual plan nodes. This lets teams analyze operator-level performance, data flow, and throughput directly from plan output — helping diagnose slow or memory-heavy offline queries.
October 23, 2025
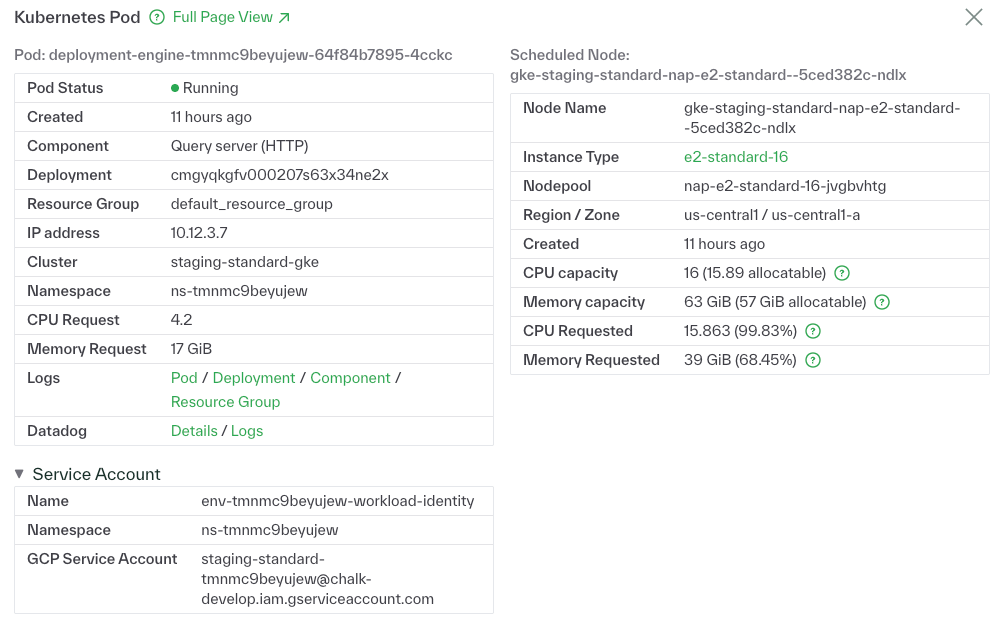
Environment Visibility
Pods now display their Kubernetes service account, namespace, and role ARN. This makes deployment and debugging more transparent for engineers from within Chalk.
Check the pod view in your Chalk environment to confirm service account mappings. Learn more about environment visibility in our docs.
October 14, 2025
New Chalk expressions for retrieving the top and bottom N records
Added new (materialize-able) aggregations (min_by_n/max_by_n) for computing the smallest/largest n elements based on any specified ordering column.
Easily compute features like the 5 most recent transactions or the top 3 highest value purchases; combine them with windowed aggregations to compute these at various intervals – e.g., past day, week, month, etc.
@features
class Transaction:
id: int
user_id: "User.id"
timestamp: datetime
amount: float
@features
class User:
id: int
transactions: DataFrame[Transaction]
recent_transaction_amounts: list[int] | None = F.max_by_n(_.transactions[_.amount], _.timestamp, 3)October 1, 2025
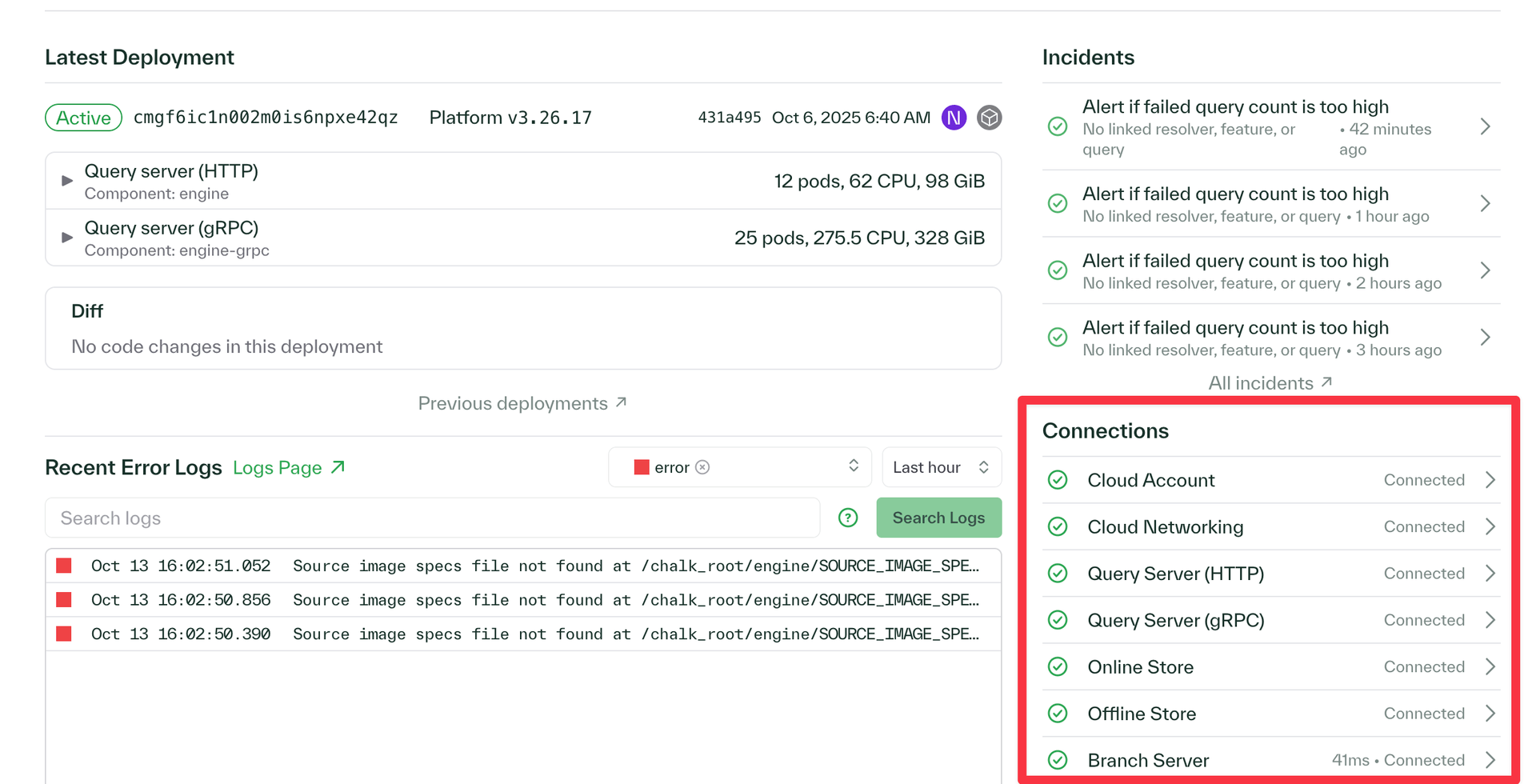
Chalk Dashboard Improvements
- Custom role creation and assignment functionality, enabling specialized roles like "Machine Learning Scientist" and "Platform Engineer"
- You can now search and filter environment variables in your Chalk dashboard
- Added a connections pane to the overview section of Chalk dashboard that shows the health status of each underlying service in your Chalk deployment
September 26, 2025
Derive features at query time with Chalk's Dynamic Expressions
Dynamic expressions enable you to compute new features on-the-fly during online queries without needing to define them in advance. Leverage Chalk's extensive function library directly in an online query to build adaptive systems that respond to changing requirements without code changes or deployments; this enables:
- Rapid experimentation, A/B testing, and hotfixes to feature logic
- Customization and conditional logic based on user context, business rules, etc.
- Seasonal or time-sensitive feature adjustments (e.g., holiday promotions)
Added new filtering options to Chalk's log explorer
The log explorer now supports escaped quotes and also negation--making it easier to filter out unwanted results. Clicking on a log operator toggles it to negation to filter out logs e.g. from a particular service.
Improvements to Chalk's diff viewer
Enhanced Chalk's diff viewer to show the entire file contents for added/removed files instead of just file names; helps track feature and resolver changes between deployments and branches.
New Chalk expression for computing the top most common values for a field
Added a new windowed aggregation (approx_top_k), for computing an approximation of the most common values in a field. Takes in a required k parameter, such as approx_top_k(k=5) for the five approximately-most common values.
@feature
class User:
id: int
transactions: DataFrame[Transaction]
most_common_transaction_category: Windowed[list[str]] = windowed(
"1h",
max_staleness="15m",
expression=_.transactions[
_.category,
_.at > _.chalk_window,
].approx_top_k(k=5)
)Chalk developer experience improvements
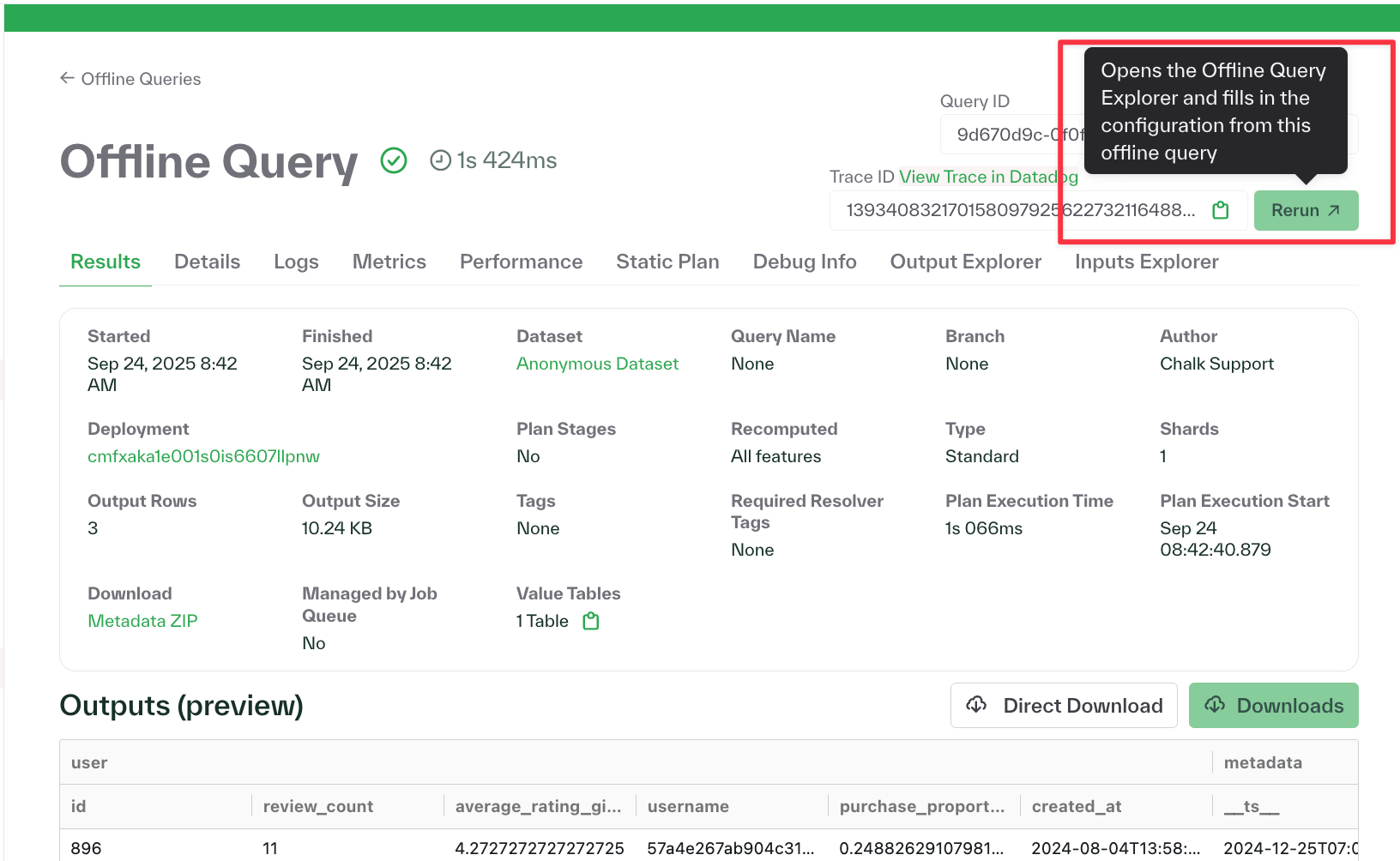
- Re-running an offline query from the Chalk Dashboard auto-fills the input parameters with the previous values for easier experimentation
- Added support for aggregations over Vector types (sum, mean)
- Pod metrics e.g. request count, etc. are now easily exportable from the Chalk Dashboard (as a CSV)
July 30, 2025
Chalk diff viewer
New chalk diff command for visualizing code differences across deployments and branches. The diff viewer highlights additions, deletions, and modifications in a color-coded format, making it easy to spot changes at a glance.
Compare any two branches
chalk diff --branch=<branch_name> --other-branch=<other_branch_name>
Compare a branch with main (default)
chalk diff --branch=<branch_name>
Compare two specific deployments
chalk diff --deployment-id=<deployment_id> --other-deployment-id=<other_deployment_id>
Compare a deployment with main branch
chalk diff --deployment-id=<deployment_id>
Chalk's Online Query Explorer now supports viewing has-one and has-many relationships
Chalk's Online Query Explorer now supports querying has-one and has-many relationship joins directly in the dashboard. When exploring a feature like User, you can now run online queries that include data from related features such as Profile (has-one) and Transfers (has-many) without leaving the dashboard interface.
Chalk dashboard improvements
- Aggregation backfills, which can be viewed from Chalk's Offline Query page now also include a table of the features that have been persisted with the backfill into your online store
- Errors encountered while deploying a branch now bubble up to the branch deployment page in the Chalk Dashboard
- Deactivated users are now visible in UI for more efficient management of inactive accounts
June 23, 2025
Process images with Chalk's builtin chat completion API
Chalk's chat completion API now supports multimodal inputs, enabling you to process images alongside text in your LLM workflows. This enhancement allows you to:
- Pass images directly to vision-capable models like GPT-4o
- Combine text and image inputs in a single prompt
- Extract structured information from visual content
@features
class Receipt:
image_url: str
image_response: P.MultimodalPromptResponse = P.completion(
model="gpt-5.1",
messages=[
P.message(
"system",
[
{"type": "input_text", "text": "describe this image"},
{"type": "input_image", "image_url": _.image_url},
],
),
],
)Workspace audit logs and monitoring
The audit log page provides comprehensive tracking of workspace changes, helping you maintain security compliance, troubleshoot issues, and understand your team's activity. Navigate to the audit logs page from the Chalk dashboard by going to Settings → Audit Logs.
The audit log captures:
- Timestamps
- Users or service accounts that made changes
- API endpoints accessed
- Descriptions of the operation
- Success/failure status
- IP addresses
- Trace IDs for debugging
Enhanced metadata export for online queries
Added a "Full Export" option that includes both query metadata and the actual input/output data (query_values.parquet) to the online queries page. Each export includes query execution details, configurations, query plans, data values, and GraphQL information.
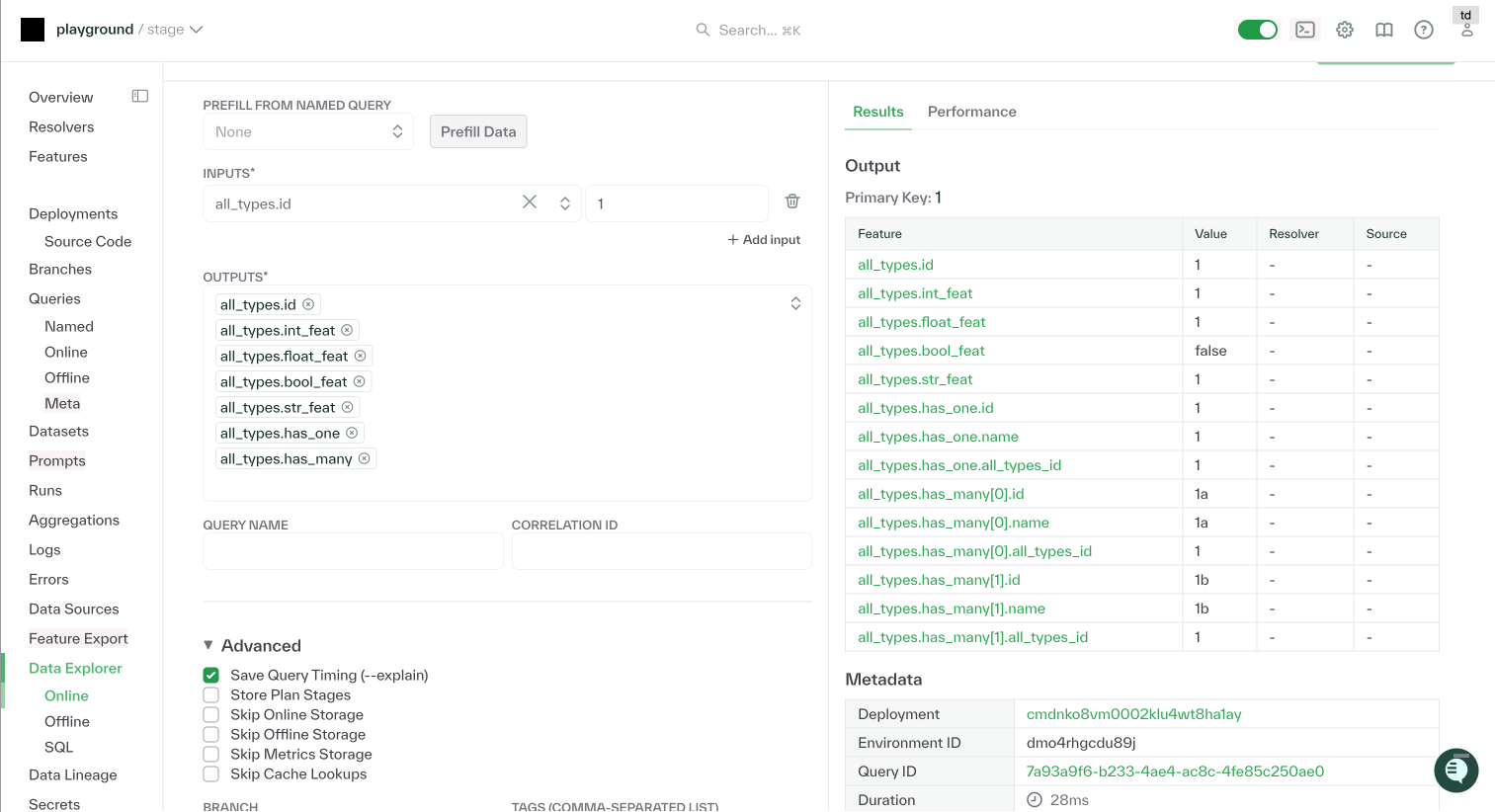
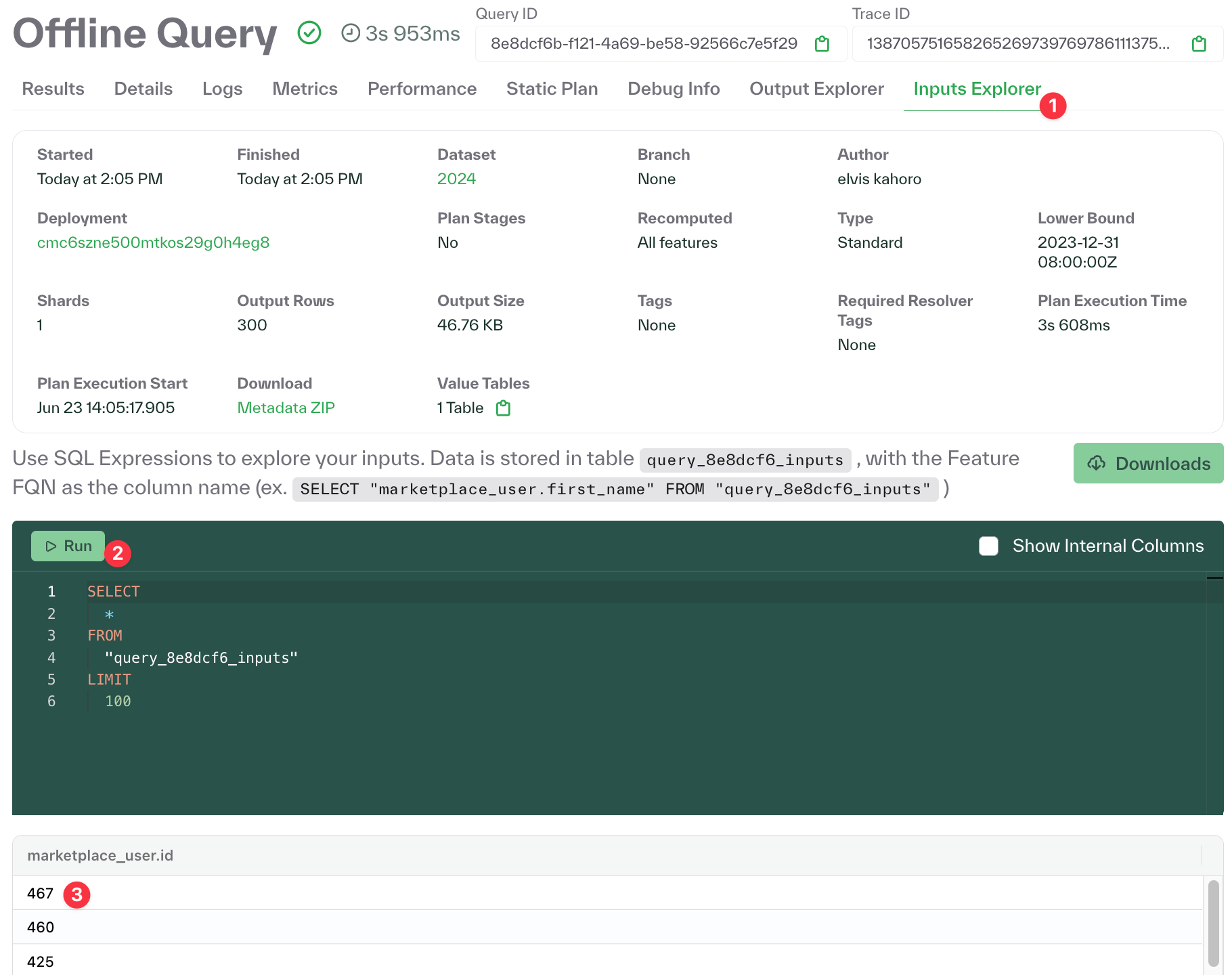
Added an offline query input explorer
Chalk's offline query explorer makes it easy to inspect, debug, and validate your offline query results through interactive SQL queries and data visualization.
We've introduced an Inputs Explorer that makes it easier to see the inputs of the offline queries that you're running. Having visibility into both inputs and outputs provides a complete picture of your offline query lifecycle, making it easier to troubleshoot issues and optimize query performance.
June 6, 2025
New documentation on optimizing and verifying static Python resolvers
We've added a new page to our docs that serves as a primer on how Chalk optimizes static Python resolvers. You can verify if your resolvers are being accelerated by checking the query plan page—optimized resolvers are highlighted in yellow and marked as "accelerated". Python resolvers that cannot be optimized will show an error explaining why. We've extended support for accelerating Python expressions that
- cast from strings to integers
- contain enums that are inherited from other enums
- use zip and enumerate built-ins
- returns a list of another feature class
@online
def get_search_results_documents(
query_text: SearchQuery.text,
) -> SearchQuery.documents:
# requests gets accelerated
docs = requests.get(f"{BASE_URL}/vector_search/{query_text}"
headers=HEADERS,
)
# returning a list of another feature class is also accelerated
return [
Document(
query_id=query_text,
content=doc.content,
title=doc.title,
similarity_score=doc.similarity_score,
metadata=doc.metadata,
rank=rank,
)
# enumerate built-in is accelerated
for rank, doc in enumerate(docs)
]
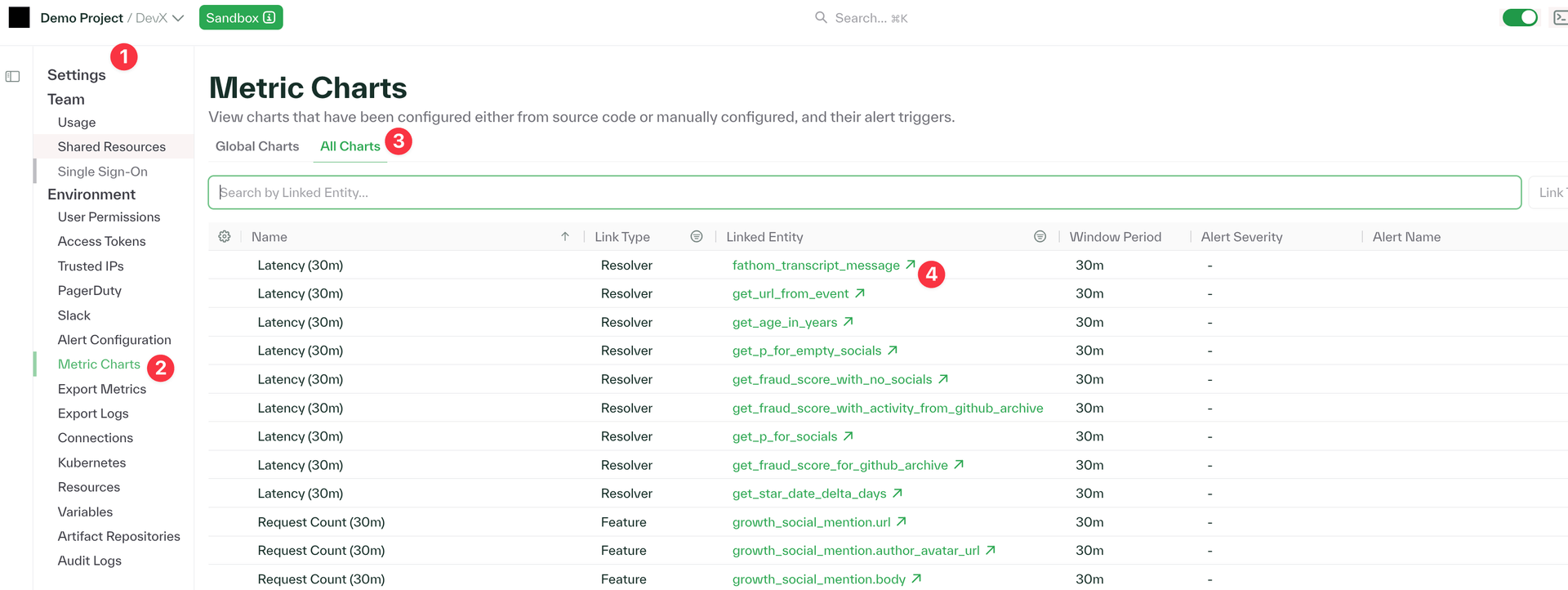
Easily view all of your charts from the Settings page of Chalk Dashboard
We have added a new "All Charts" tab under the "Metric Charts" section of your Settings that displays all charts available in Chalk. The new tab shows:
- A complete list of all the charts in your environment
- Chart types and categories
- The entities or features that each chart is attached to (for example, a link to view the chart)
- Any associated alerts
May 30, 2025
Export user permissions as a CSV
You can export information about all users across all environments as a CSV file for easy auditing and compliance reporting. This export, available from the User Permissions section in your Chalk Dashboard, generates a CSV containing each user's name, email address, unique Chalk ID, and their assigned roles for every project-environment combination in your workspace.
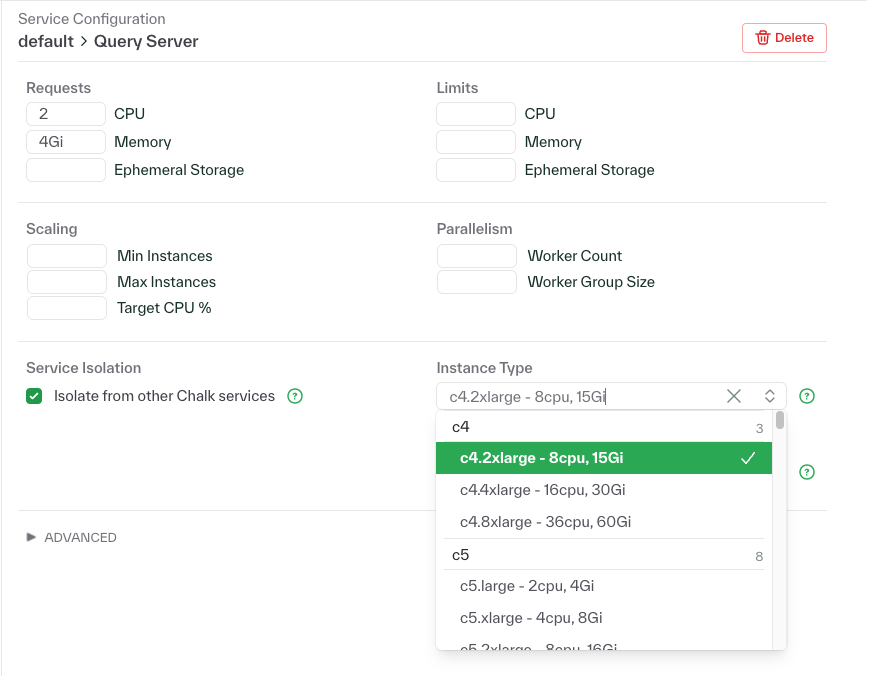
Chalk resource configuration and dashboard improvements
- Service isolation, which ensures your workloads run on dedicated infrastructure with 1:1 pod-to-node isolation, is now easily toggle-able using a checkbox in the configuration options.
- The instance type selector is now a searchable dropdown that displays machine specifications and validates your resource requests in real-time. If you request more CPUs than the selected instance can provide, you'll see an immediate warning preventing deployment failures and reducing troubleshooting time.
- Added a dropdown for selecting which node pools services should run on. When selected, services will be directed to the specified node pools with automatic toleration handling. This prevents services from being assigned to incompatible node types and ensures pods are scheduled correctly on tainted nodes.
May 23, 2025
Embed Chalk expressions in versioned features
Feature versions support Chalk expressions, allowing you to define different computation logic for each version of a feature. This makes it easy to experiment with new feature definitions—you can create multiple versions with different expressions and test them side-by-side to compare their accuracy, performance, and business impact.
@features
class Merchant:
id: str
fulfilled_orders: int
total_orders: int
customer_rating: float
max_rating: float
trust_score: float = feature(
default_version=2,
versions={
1: feature(
description="Trust score based on orders",
expression=_.fulfilled_orders / _.total_orders,
),
2: feature(
description="Trust score based on CSAT",
expression=(_.customer_rating / _.max_rating),
),
}
)gRPC support for TypeScript SDK
Our gRPC clients are faster than their HTTP counterparts, offering reduced latency and improved query response times. We've published a migration guide for transitioning from the HTTP client to the new gRPC implementation in TypeScript. The function signatures are identical, making for a seamless transition with minimal code changes. Currently, the gRPC client supports query(), queryBulk(), and multiQuery() operations, covering the most common query use cases.
import { ChalkGRPCClient } from "@chalk-ai/client"
import { FeaturesType } from "local/generated_types";
interface FeaturesType {
"user.id": string;
"user.fraud_score": number;
}
const client = new ChalkGRPCClient<FeaturesType>();
const result = await client.query({
inputs: {
"user.id": "1",
},
outputs: ["user.fraud_score"],
});
console.log(result.data["user.fraud_score"].value);May 16, 2025
We now support ClickHouse as a Chalk data source
Chalk can connect to your ClickHouse database and other data sources with standard SQL syntax. Here's an example of a SQL resolver for pulling transaction data:
-- type: online
-- resolves: Transaction
-- source: clickhouse
select
transaction_id,
transaction_timestamp,
transaction_amount,
user_id,
product_category,
transaction_channel,
payment_method_type,
transaction_status,
store_location_region
from
transactionsRefreshed our "What is Chalk?" overview and documentation page
We've refreshed our introductory documentation with more comprehensive examples and new sections that showcase how Chalk serves different roles (AI Engineers, Data Scientists, and Data Engineers).
Case study with MoneyLion—a leading fintech for banking, investing, and credit building
With Chalk, MoneyLion replaced fragmented Java microservices and manual rewrites with a unified Python-first feature platform. MoneyLion now iterates in hours instead of weeks, replacing their "slow and disjointed" prototype-to-production cycle with a central feature catalog that makes starting "every use case from scratch" a thing of the past.
May 2, 2025
Retrieve historical feature values with SQL
Feature values can now be retrieved from historical storage with SQL enabling direct access to previously computed values with the option to fall back to on-demand re-computation when needed.
Manage traffic spikes with per-pod rate limiting
Rate limiting now supports per-pod controls through rate-per-second and concurrency parameters, enabling customers to maintain performance targets even during high traffic periods. The configurable limits help prevent resource exhaustion and ensure consistent application behavior under varying loads.
Quarterly product update Spring 2025
We've published our quarterly product update, which summarizes improvements and updates from this past Spring, including expanded Python-to-C++ compilation, selective feature persistence controls, and enhanced observability tools.
April Events Roundup
We've published a recap of the various AI and data conferences our team attended in April 2025. The blog post covers our participation at NexGen Banking Summit, VeloxCon, Agents & GenAI Infrastructure Summit, OptimizedAI Conference, and Data Council, including key talks and insights we shared about building infra for real-time ML at scale.
April 21, 2025
Presented at VeloxCon 25 (April 15-16 at Meta HQ)
Nathan Fenner presented how Chalk leverages Velox as a common compute engine for both online and offline queries:
- Improvements to Velox's expression analysis for low-latency applications
- Custom enhancements for avoiding redundant computations and a specialized online hash join
- Our symbolic Python interpreter that automatically converts Python feature transformations into efficient Velox expressions
Check out the talk (18 mins) on our YouTube page!
Faster HTTP requests using Chalk Expressions
Chalk functions now support direct HTTP requests via the chalk.functions.http module, enabling you to call external APIs with high performance and without the overhead of Python. The HttpResponse type provides access to response data including status codes, bodies, headers, and the final URL after redirects.
import chalk.functions as F
from chalk import Primary, _
from chalk.features import features
from chalk.functions.http import HttpResponse
@features
class ExternalAPI:
id: int
api_endpoint: str
# GET request returning string response
api_response: HttpResponse[str] = F.http_get(_.api_endpoint)
status_code: int = _.api_response.status_code
response_body: str = _.api_response.body
headers: dict[str, str] = _.api_response.headers
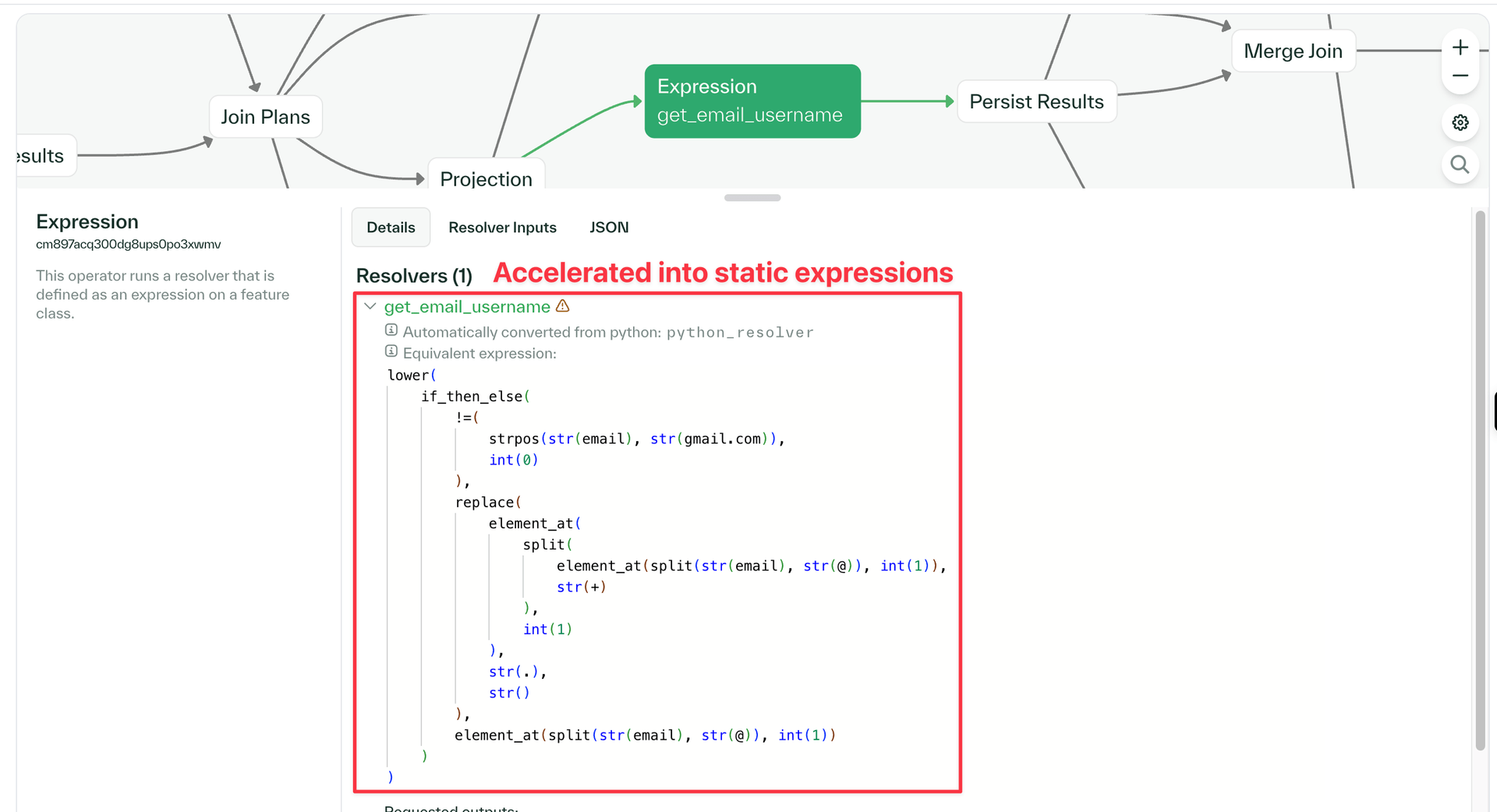
final_url: str = _.api_response.final_urlChalk accelerated Python resolvers are colored as yellow
Symbolic Python resolvers accelerated by Chalk are now highlighted in yellow in the query plan viewer (standard Python resolvers remain purple), making it easier to differentiate resolvers that are accelerated or candidates for symbolic execution.
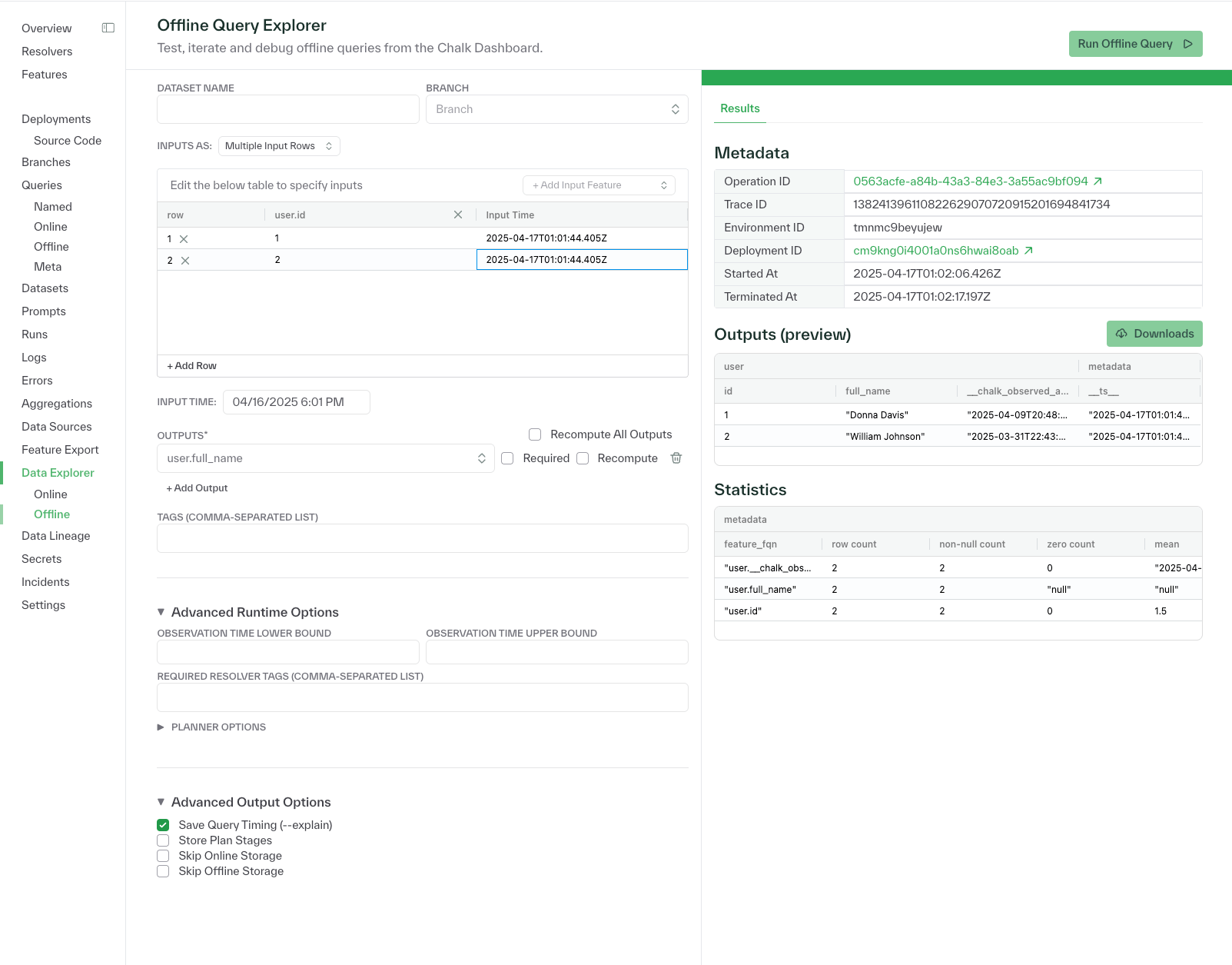
New offline query explorer added to the Chalk dashboard
The offline query explorer includes a new grid/table view for entering multiple input features in a single query, with support for adding, editing, and deleting rows and the option to recompute outputs as needed. The updated interface enhances visibility into these query results through interactive preview panels, comprehensive statistics displays, and detailed metadata exploration.
April 4, 2025
Chalk developer experience improvements and engineering blog post
We've expanded the coverage for the types of Python resolvers that Chalk can statically compile into C++, speeding up computation. Check out our new engineering blog post for a deep dive into how our Symbolic Python Interpreter works.
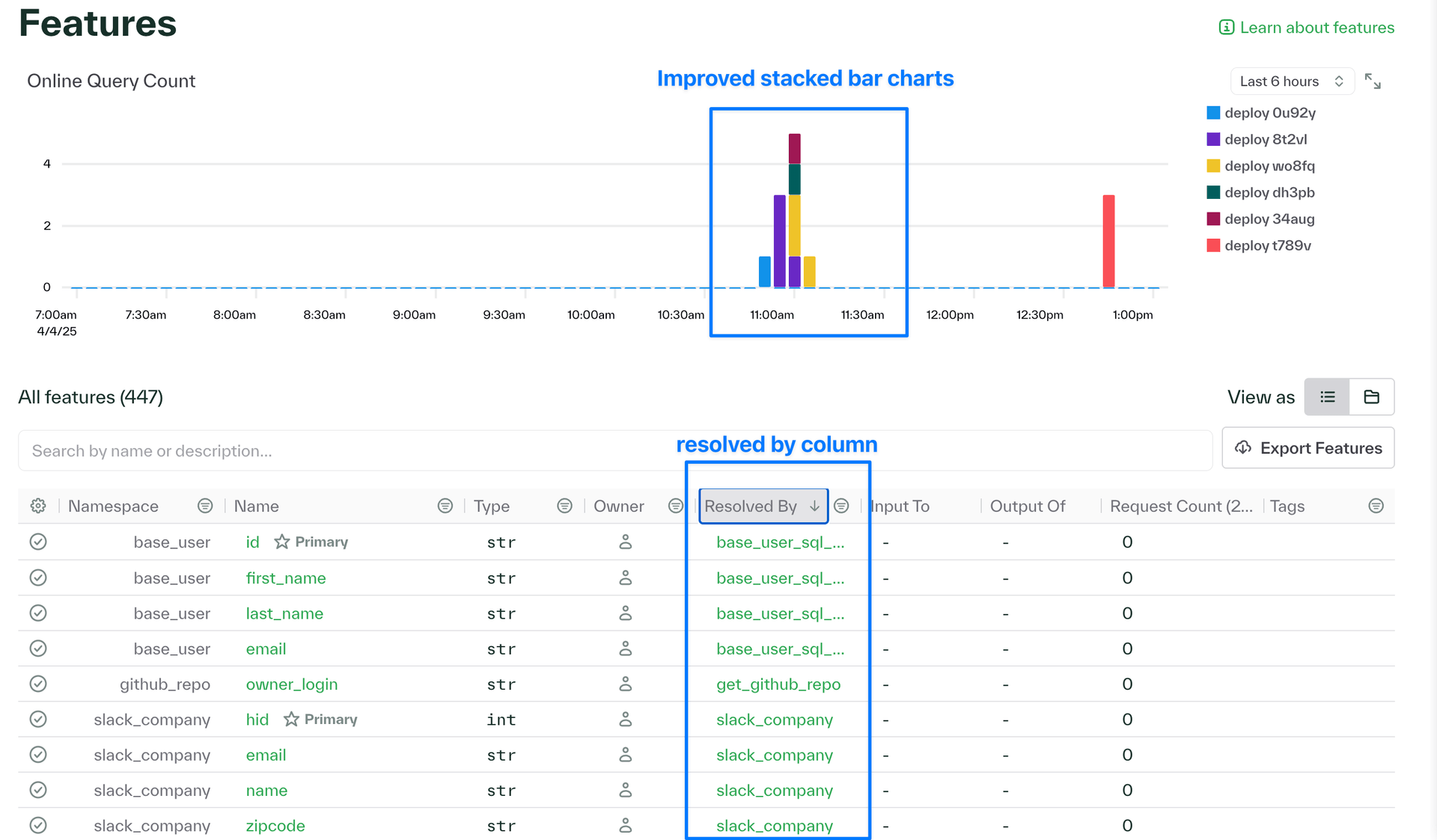
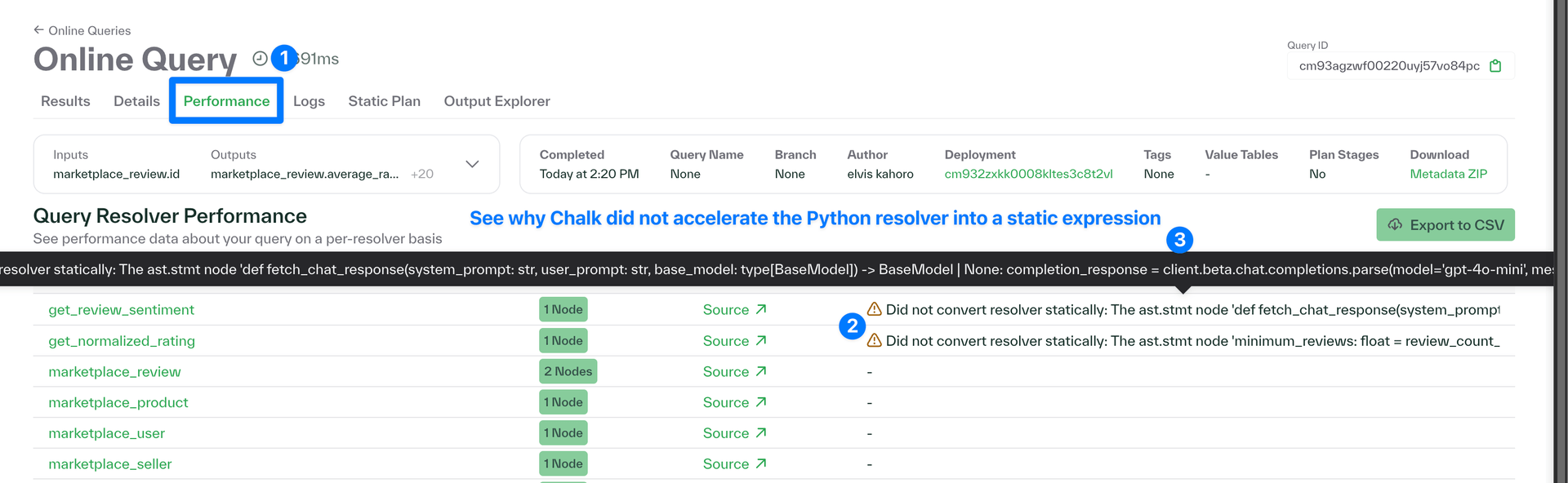
Chalk dashboard improvements
- Improved how we render stack bar charts within the Chalk dashboard
- Can now filter out and explicitly view Scheduled Queries from the Offline Queries page
- New "Resolved by" column in the features page clearly displays the source resolver for each feature improving traceability
- The Offline Queries page now includes a "Request" button in the details section that displays the parameters used when the query was processed
- Added a "Performance" tab when viewing an Online Query that enables inspecting each resolver referenced e.g. SQL query, code, input and output params, and why it may have not been statically accelerated
March 26, 2025
Case study with Apartment List—a thriving apartment rental marketplace transforming search with real-time personalization
With Chalk, Apartment List delivers instant apartment recommendations with real-time price and location flexing, dynamically adapting to user behavior while making low-latency calls to third-party services for the most current pricing information.
Chalk developer experience improvements
Added store_offline and store_online overrides for features with max staleness, making it easy to exclude features from being persisted, particularly helpful for intermediate features that do not need to be saved e.g. very long text.
@features(max_staleness="infinity")
class Document:
id: str
file_type: str
corpus_text: str = feature(store_offline=False, store_online=False)
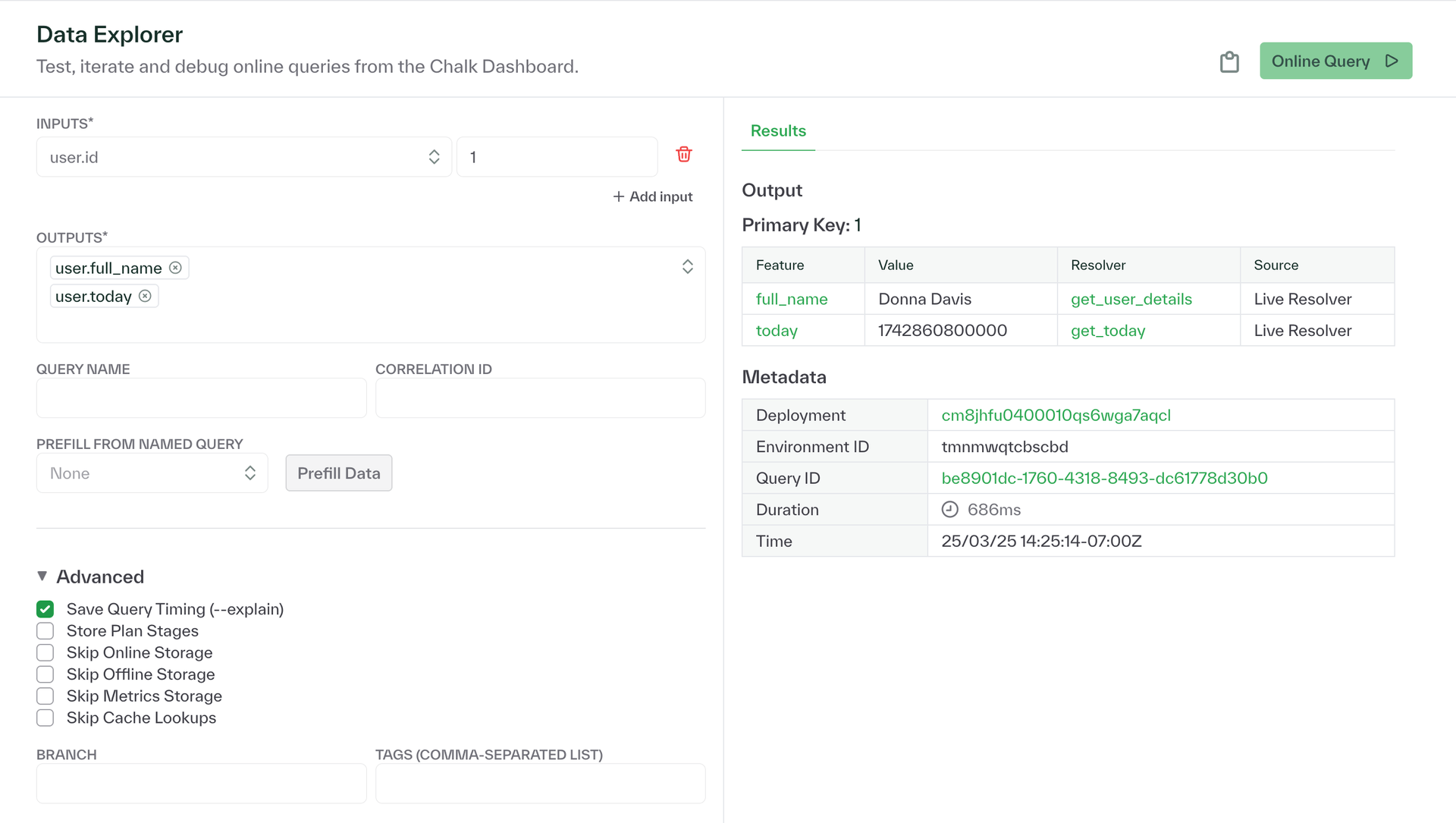
extracted_feature_from_corpus_text: strChalk dashboard improvements
Chalk's Data Explorer now displays the source of each feature e.g. "Live Resolver"
March 14, 2025
Breaking changes to Chalk Client's Go SDK (1.2.0)
Released v1.2.0 of the Chalk Go Client which introduces some breaking changes, most notably:
- The gRPC implementation of Client is removed and replaced with a consolidated NewGRPCClient constructor--configuration remains mostly unchanged.
OnlineQueryBulk removed to prevent inefficient data conversions, migrate toOnlineQueryBulk`.- Use
GRPCOnlineQueryBulkResult.UnmarshalIntofor structured responses. - Most
GRPCClientmethods now return user-friendly wrappers around proto responses, exposing raw responses via RawResponse. Errors are now lifted properly.
Chalk developer experience improvements
- Singletons can be used to filter
DataFramesand has-many relationships. - New Chalk functions:
max_by_nandmin_by_nChalk functions: retrieve the top n rows with the maximum and minimum values from a specified column in a DataFrame or has-many relationship, equivalent tosort_by(sort_col, DESC or ASC).head(n)[result_col] - New Chalk functions:
array_median,array_average,array_sum,array_stddev - Expanded Python resolver acceleration to support strings manipulation e.g. slices, substrings, and reverses
Chalk dashboard improvements
- Chalk deployments running on AWS now support manually creating and editing node pools via the dashboard, making it easier to organize and manage different groups of worker nodes in a cluster. This helps distribute workloads more efficiently and scale specific groups as needed.
- The query plan viewer now displays the static expressions generated to accelerate Python resolvers
February 27, 2025
Case study with Verisoul--a leading provider of real-time fake account detection
With Chalk, Verisoul iterates on fraud signals, deploys new updates in hours, and increases detection accuracy.
Easily import feature classes with Chalk Client when experimenting locally
We have implemented two new functions for Chalk Client to aid in local experimentation: client.load_features() and client.get_or_create_branch().
client.load_features()imports your environment's feature classes into the global namespace, making it easier to reference features when running queries with Chalk Client in a Jupyter notebook.client.get_or_create_branch()enables programmatically creating branches or fetching branches for local experimentation.
We've also updated our guide for developing with Jupyter Notebooks.
Breaking changes to Chalk Client's Go SDK
Released v1.0.0 of the Chalk Go Client which introduces some breaking changes, most notably:
- Removed custom error structs which helps us standardize how Client errors are bubbled up
- Added
context.Contextto all Client methods enabling us to specify timeouts and custom loggers
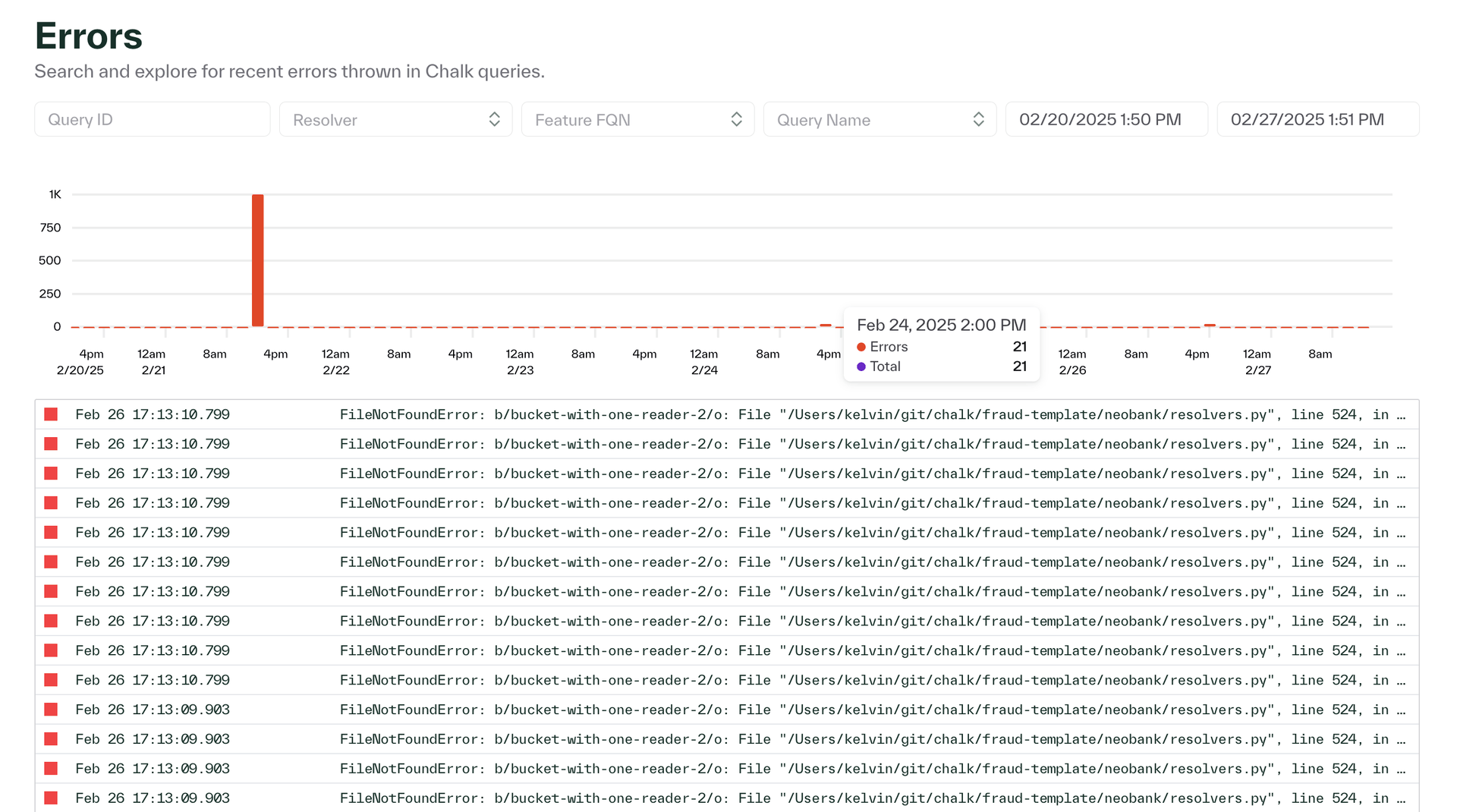
Chalk dashboard improvements
- The deployment metrics chart can now be filtered by named (custom) tags
- The Chalk dashboard has a new errors page for viewing exceptions and issues with Chalk queries
February 20, 2025
Persist Datasets to your AWS Glue Catalog
ML teams often use offline queries to build training sets by pulling historical data and loading multiple features at specific points in time. We call the results returned from these offline queries Datasets. Chalk supports exporting Datasets back into your AWS Glue catalog, letting other teams discover them and enabling downstream analytical workflows.
from chalk.integrations import GlueCatalog
dataset = client.offline_query(...)
catalog = GlueCatalog(
name="aws_glue_catalog",
aws_region="us-west-2",
catalog_id="123",
aws_role_arn="arn:aws:iam::123456789012:role/YourCatalogueAccessRole",
)
dataset.write_to(destination="database.table_name", catalog=catalog)Chalk dashboard improvements
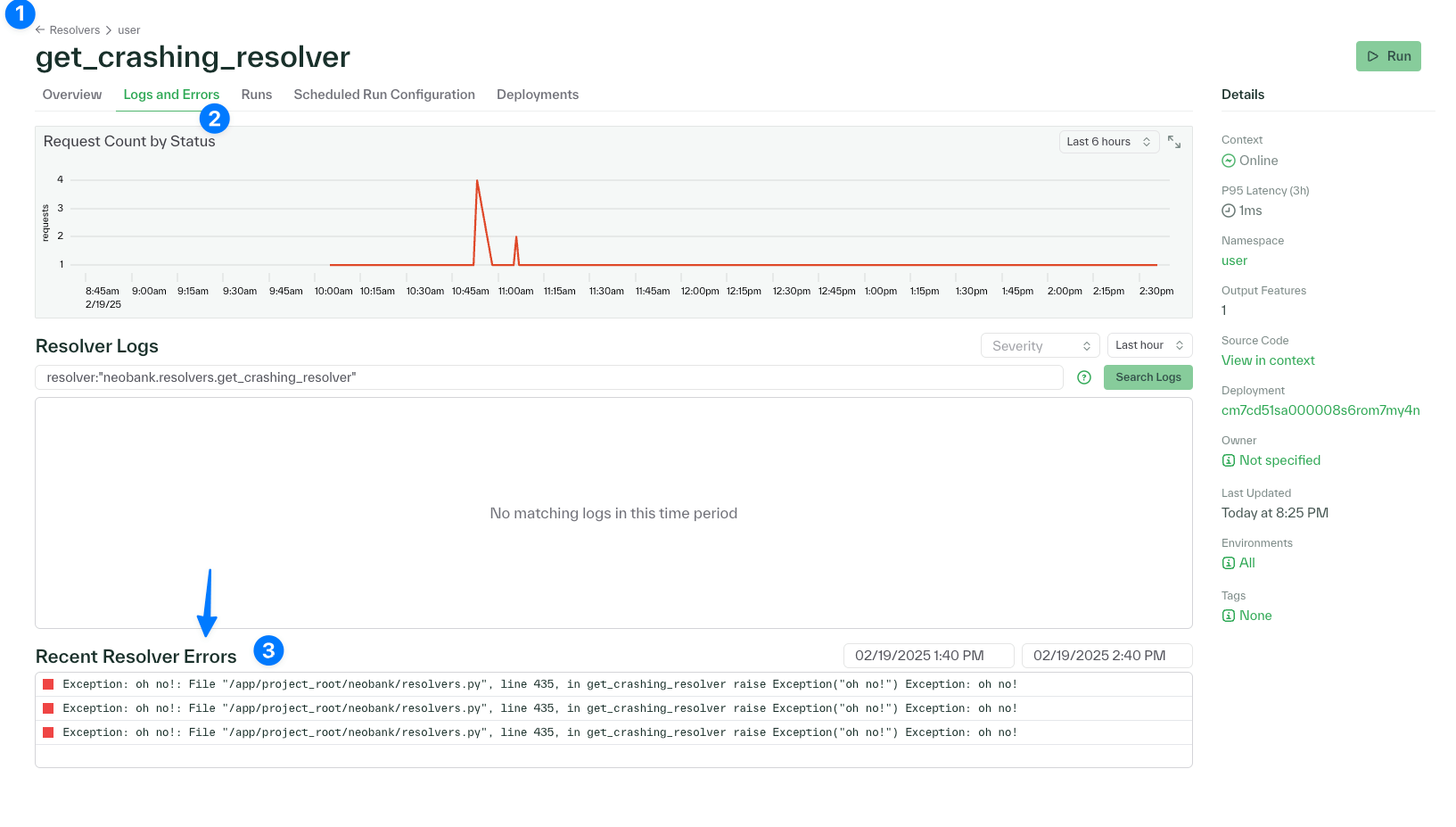
- The Resolvers page in the Chalk dashboard now has a Request Count column; quickly sort and see which resolvers are being called the most
- The pages for Named Queries and Resolvers now also include errors, use the "Logs and Errors" tab to switch to this filtered view
- Click and drag your mouse within the time series graph to zoom in into a time interval and filter down the errors table
February 13, 2025
Expressive filtering: DataFrames & Has-Manys now support Chalk Expressions!
Has-many (DataFrame) features can now be filtered using any Chalk Expression, unlocking new design patterns and improving DevX!
high_cash_flow_merchants: int = _.df[_.id].where(_.total_deposit_amount + F.abs(_.total_withdrawn_amount) > 10**7).count()
average_revenue_from_amazon_retailers: float = _.df[_.revenue].where(F.starts_with(_.merchant_code, "amazon-")).mean()
publicly_traded_not_tech: int = _.df.where((_.industry != "tech") & (_.is_public == True)).count()
holiday_shifts: int = _.df.where(F.is_us_federal_holiday(_.timestamp)).count()
expenses_past_month_with_three_day_lag: float = _.expenses[_.amount].where(_.timestamp - timedelta(days=3) > _.chalk_now - timedelta(days=31)).sum()Has-many joins using composite keys (Chalk Expressions)
A composite key is a combination of two or more attributes that together uniquely identify an entity. Link feature classes with composite keys created by a Chalk Expression or through referencing multiple features in a has-one or has-many join. Here's a has-one relationship between User and Profile classes using both user_id and email as composite join keys.
@features
class User:
id: str = _.alias + "-" + _.org + _.domain
org_domain: str = _.org + _.domain
org: str
domain: str
alias: str
# join with composite key
posts: DataFrame[Posts] = has_many(lambda: User.id == Post.email)
# multi-feature join
org_profile: Profile = has_one(lambda: (User.alias == Profile.email) & (User.org == Profile.org))
@features
class Workspace:
id: str
# join with child-class's composite key
users: DataFrame[Users] = has_many(lambda: Workspace.id == User.org_domain)Chalk runtime improvements
- Chalk attempts to convert each Python resolver into a chain of static expressions that can be accelerated using the function's AST. We've expanded the parser with preliminary support for accelerating Python for loops.
- Improved how we incorporate traffic from Kafka Streams into our (KEDA) autoscaler
Chalk dashboard improvements
- Reduced the chart load times of large offline queries and queries run through the Data Explorer page of the Chalk dashboard
- Added support for configuring Chalk query contexts and planner options in the Data Explorer page
February 6, 2025
Chalk dashboard improvements
- Added a configuration page for modifying Chalk's connection to your artifact registry e.g. AWS CodeArtifact and Google Artifact Registry
- The deployments overview page now includes hyperlinks to the source code associated with each deployment
- Added a unified page for viewing scheduled resolvers, queries, and pending backfills
- The detailed performance metrics now displays metrics from a query's physical plan e.g. peak memory, input bytes, output rows
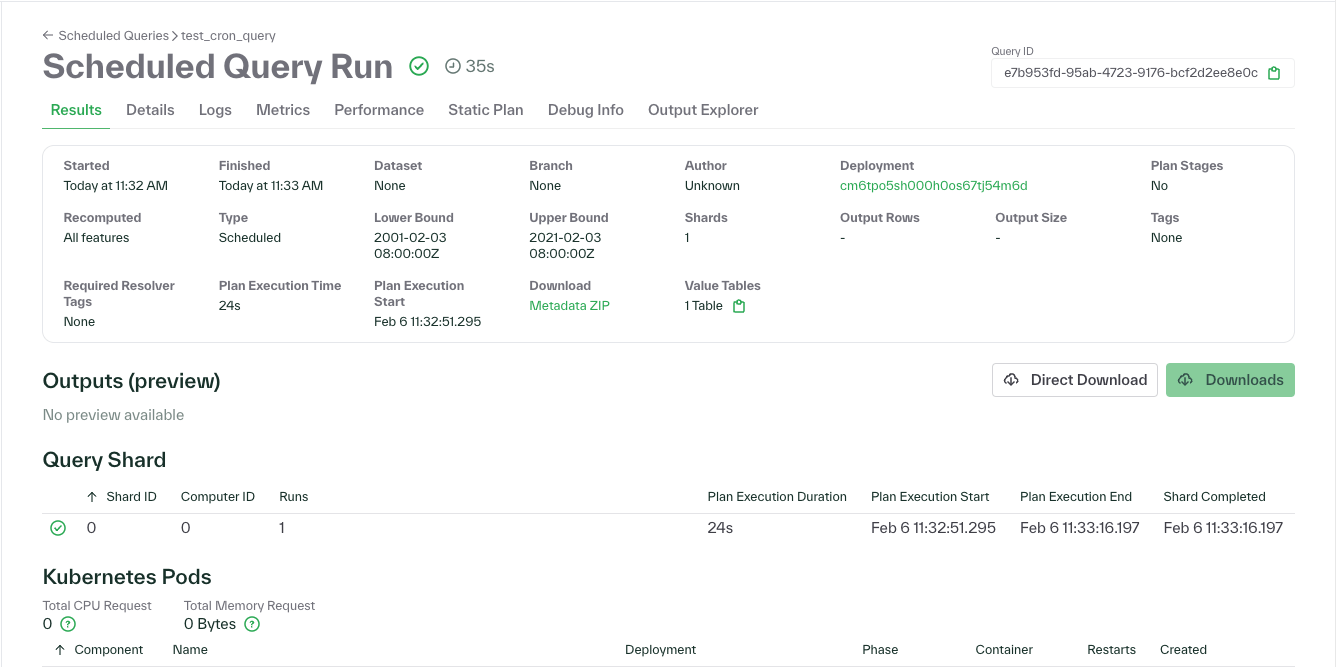
January 30, 2025
Support for embedding models from Vertex AI (GCP)
Chalk can automatically create embeddings for vector feature types through Open AI. We've expanded our native embed function to support Vertex, Google Cloud's AI platform.
Extended support for Now--a Chalk primitive for referencing the current time
Now is a Chalk built-in that enables us to incorporate the current time as a filter. Extending the support for Now unlocks new design patterns; build resolvers and queries that take in
- multiple ids at a single point in time
- a single id at various points in time
- multiple ids at various points in time
Easily sample historical state like all the transactions for 3 users from a particular date or include the current time when calling out to a microservice.
sample_some_transactions = offline_query(
input={Transaction.user_id: [103, 150, 170]},
input_times=[datetime(2024, 1, 1, tzinfo=timezone.utc)] * 3,
output=[Transaction],
recompute_features=True,
)Chalk branches can be deployed without requiring a local Chalkpy installation
Chalk checks your features for errors locally before deploying them to a remote branch. Normally, if chalkpy (Chalk’s Python SDK) isn’t installed locally, running chalk apply would fail. However, we can now lint branches remotely and show your validation errors in the CLI as usual.
Breaking change in the 1.0.0 major release of Chalk's Java client
This release introduces performance improvements to OnlineQueryResult.unmarshal, but with a few breaking changes:
- Unrequested features are now left as null instead of being initialized as empty objects, similarly so for unrequested dataclass features (subclasses of
StructFeaturesClass). OnlineQueryResult.unmarshalnow consumes scalarsTable, resulting ingetScalarsTable()returning an empty table post unmarshaling.
Please create a copy of your results if they need to be retained with .copy().
Chalk dashboard improvements
- Drag to zoom: Click and drag within a chart or online query to zoom into the selected timeframe; this helps drill down into your charts.
- Faster chart loads: We've improved the load times of charts in the Chalk dashboard!
- Offline queries that run with
explain=Truenow have a performance summary tab that helps trace query performance. Identify operations with their memory consumption, input size, output size, and whether the operation was blocked before executing. - The Chalk dashboard now supports directly exporting (as Parquet) any view that uses our output explorer: feature previews, datasets, offline queries, and online queries that get persisted to the offline store.
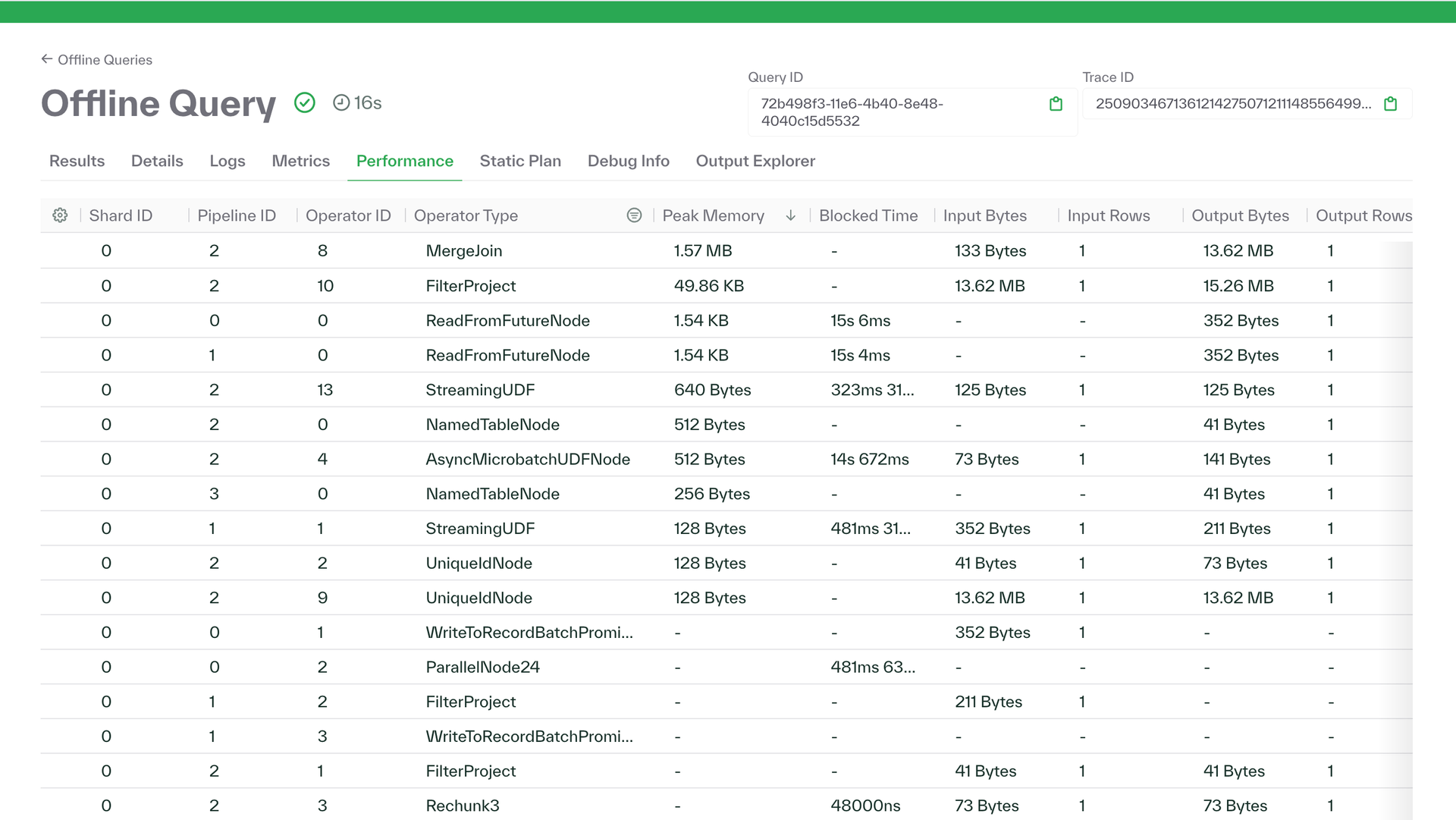
January 22, 2025
Chalk's C++ SQL Driver for Spanner now supports inputs (parameterized queries)
Chalk’s C++ driver now supports Spanner queries that explicitly accept input parameters. These resolvers now run faster, with some query latencies dropping from 24ms to 10ms.
Enhanced visibility into your Chalk deployment
The Chalk query plan viewer now highlights nodes for Chalk expressions and SQL resolvers using Chalk's C++ driver in orange. Differentiate between various node types at a glance to debug Chalk queries in less time.
The Kubernetes resource page in the Chalk dashboard has been enhanced to include data from the Kubernetes events API, increasing visibility into nodes, pods, and more objects to come. Expanding the types of events and their granularity provides better insights into jobs. These include events like node removal, pod scheduling, and deployment failures.
The query plan viewer in the Chalk dashboard now supports breadcrumbs to hyperlink to a feature’s parent in the query plan viewer, enabling quicker traversal through a feature’s lineage.
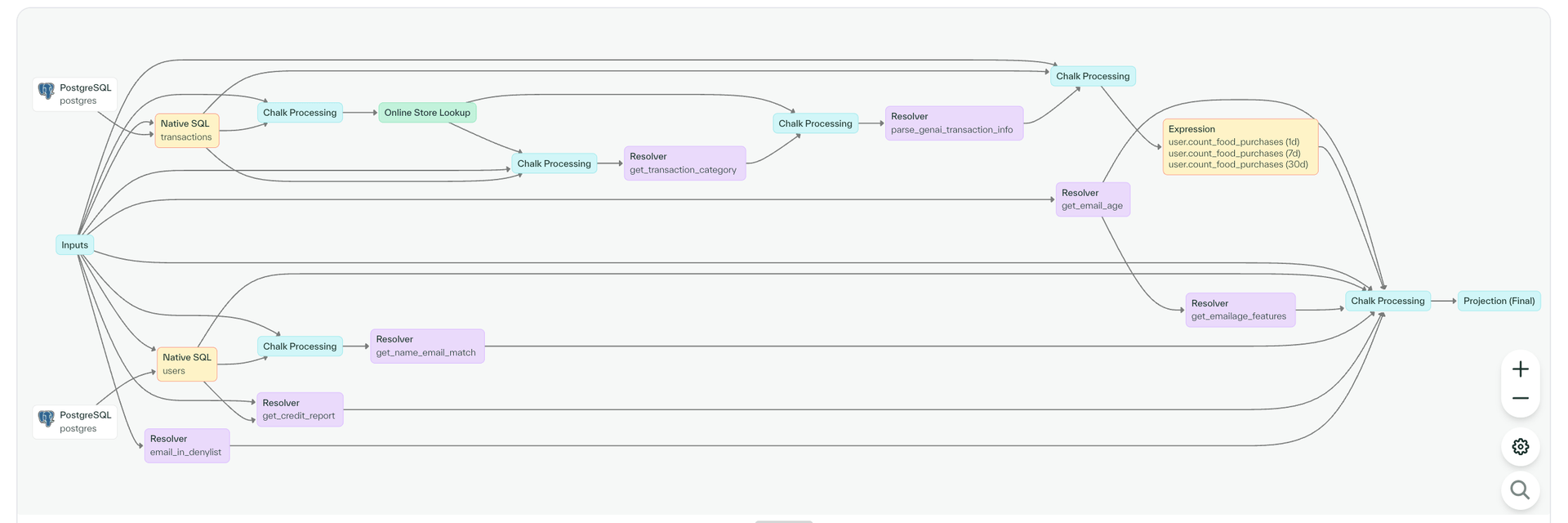
January 15, 2025
Improved the granularity at which Chalk services can be rolled back
We improved our CI/CD to support releasing new Chalk images in parallel. We also extended both the quantity and types of builds (across various Chalk microservices) that we cache, improving the speed and flexibility of Chalk rollbacks!
Kubernetes node UI enhanced for readability
We improved the Kubernetes Node UI to display additional data about the nodes in your cluster and polished the UI for compactness and readability.
Chalk dashboard bubbles up feature value metrics
The feature section of the Chalk dashboard will now show salient metrics for your top feature values. The number of observations, when features were observed, the most observed features, and more. Metrics can be sliced and grouped by filters like deployment ID, resolver, and operation type, which helps in debugging (at a glance insight into) deployments.
Query plan viewer now supports node lookups
The Chalk dashboard now also supports query plan node look ups via resolver name, node type, and the input/output features associated with the node. This makes it easier to trace the behavior of a resolver in complex query plans.
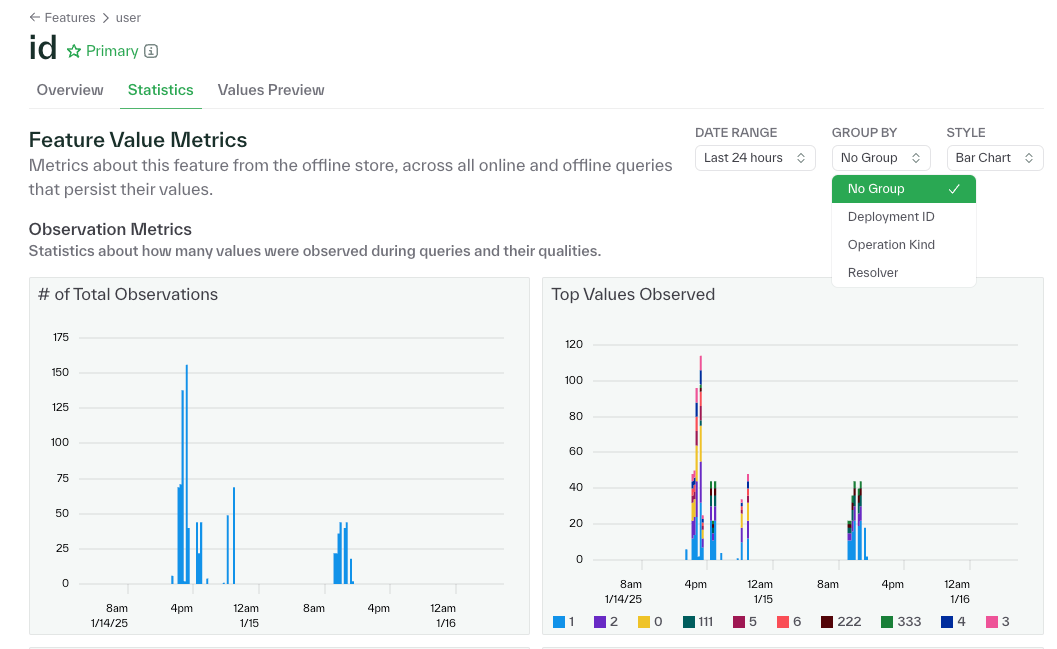
January 6, 2025
Optimized resource usage with KEDA
We've implemented KEDA (Kubernetes-based Event Driven Autoscaler) and are rolling it out to all customer clusters over the next few weeks. With KEDA, we've expanded the types of resources that can be dynamically scaled up and down during periods of reduced or no workload. We look forward to potential improvements both in the elasticity and efficiency of your deployments.
View and query logs using the CLI
Inspect your log stream the same way you would from the Chalk dashboard but with the command line:
chalk logs [--query="the same string you can put in the web ui"]
Read more about how to view logs using the Chalk CLI in our docs.
Visualize and trace your feature's data lineage with a Graph View
The Data Lineage page in the Chalk dashboard lets you track your features, specifically how they are derived, when they are referenced (Named Queries), etc. In addition to the default list view, we have implemented a graph view, making it easier than ever to trace how your features are created and connected.
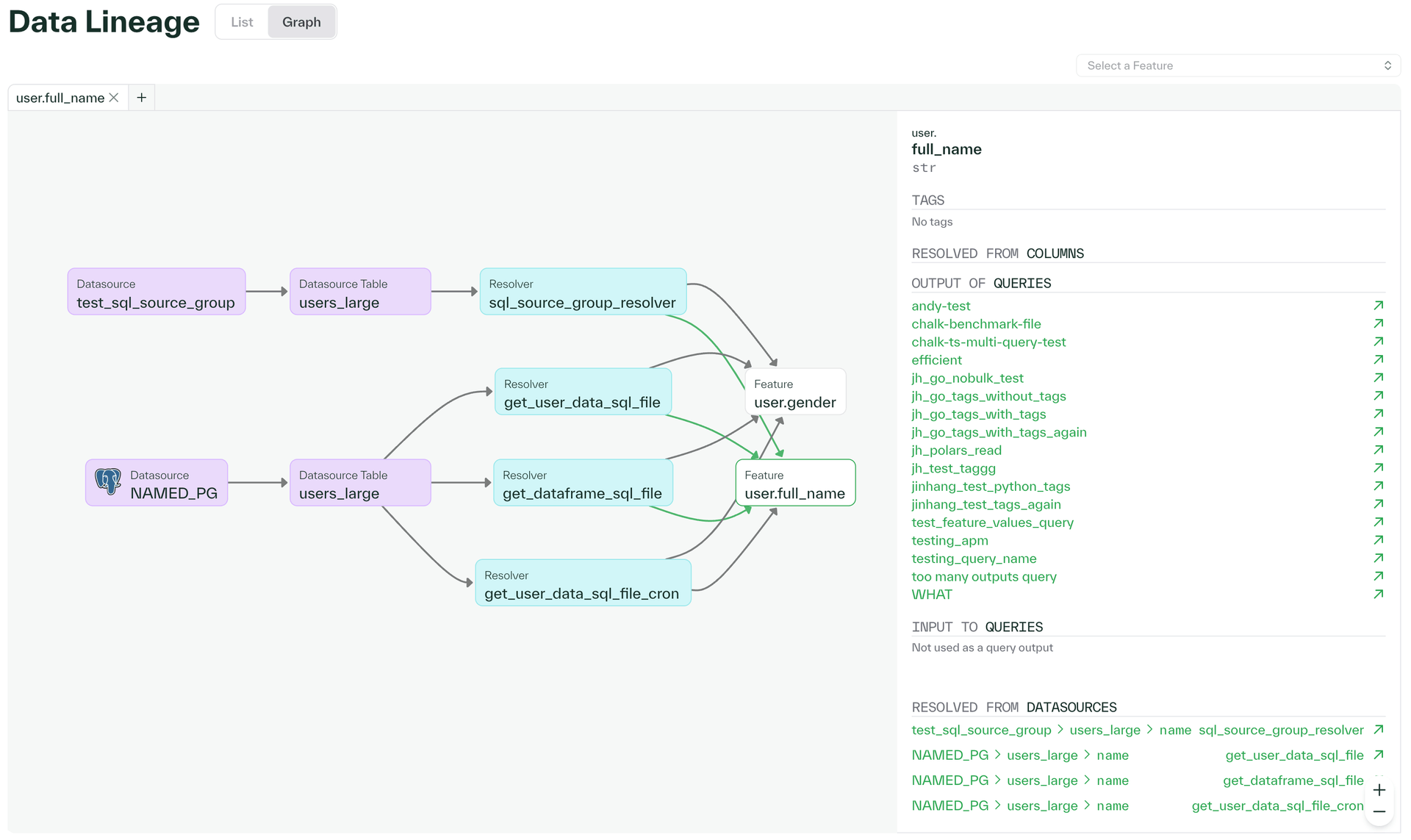
December 23, 2024
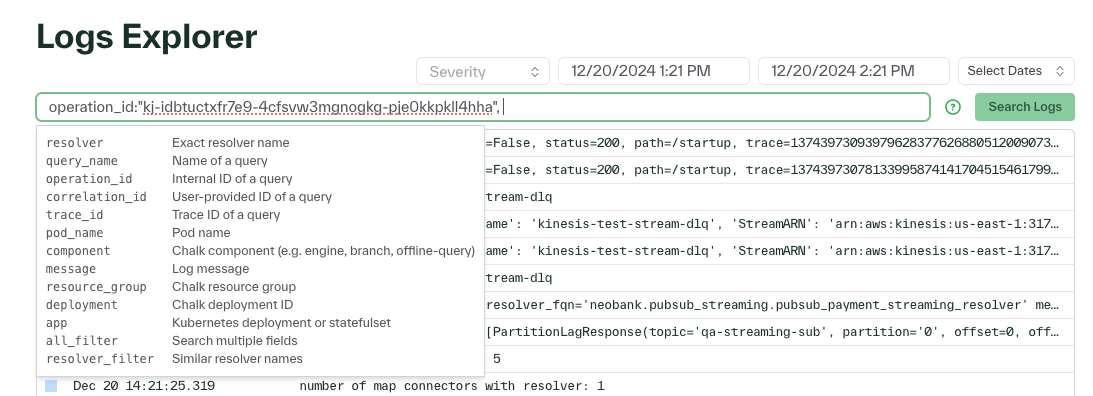
Search and filter logs by query name, log message, deployment, and more!
You can now search logs in the Logs Explorer in the dashboard using a key-value pair query format: key1:value1 key2:value2 .... This allows you to combine multiple filters at once. The Logs Explorer displays the available keywords for filtering, shown below.
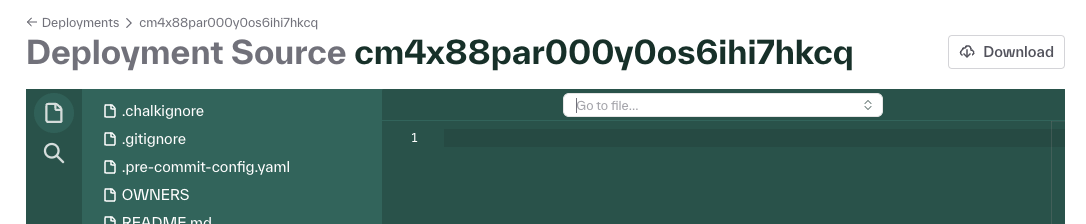
Search by file name in the source code viewer
The Source Code Viewer on the Deployments page of the dashboard has been extended! In addition to searching for keywords in your source code, you can now also search for your files by name.
Include query context in Chalk Client queries
The Chalk Client now offers a query_context field that can be accessed by Python resolvers, allowing you to pass additional information in your queries. The query_context is available for online queries, bulk online queries, and offline queries for both ChalkClient and ChalkGRPCClient, and can be tested using ChalkClient.check.
Expressions support more string, encoding, and date functions
The chalk.functions library now supports more string, encoding, and date functions that can be used in Chalk expressions. You can now use jaro_winkler_distance to compute the Jaro-Winkler distance between two strings, partial_ratio to compute the fuzzywuzzy partial ratio between two strings, and length to compute the length of a string. We've also added struct_pack to construct a struct from a mapping, year to extract the year from a date, and last_day_of_month to return the last date in the month given a date. To read more about all of the chalk.functions available for writing expressions, check out our API docs.
December 16, 2024
Source code viewer in dashboard supports text search
The source code viewer in the Deployments page of the dashboard now supports fuzzy text search across the source code for the linked deployment.
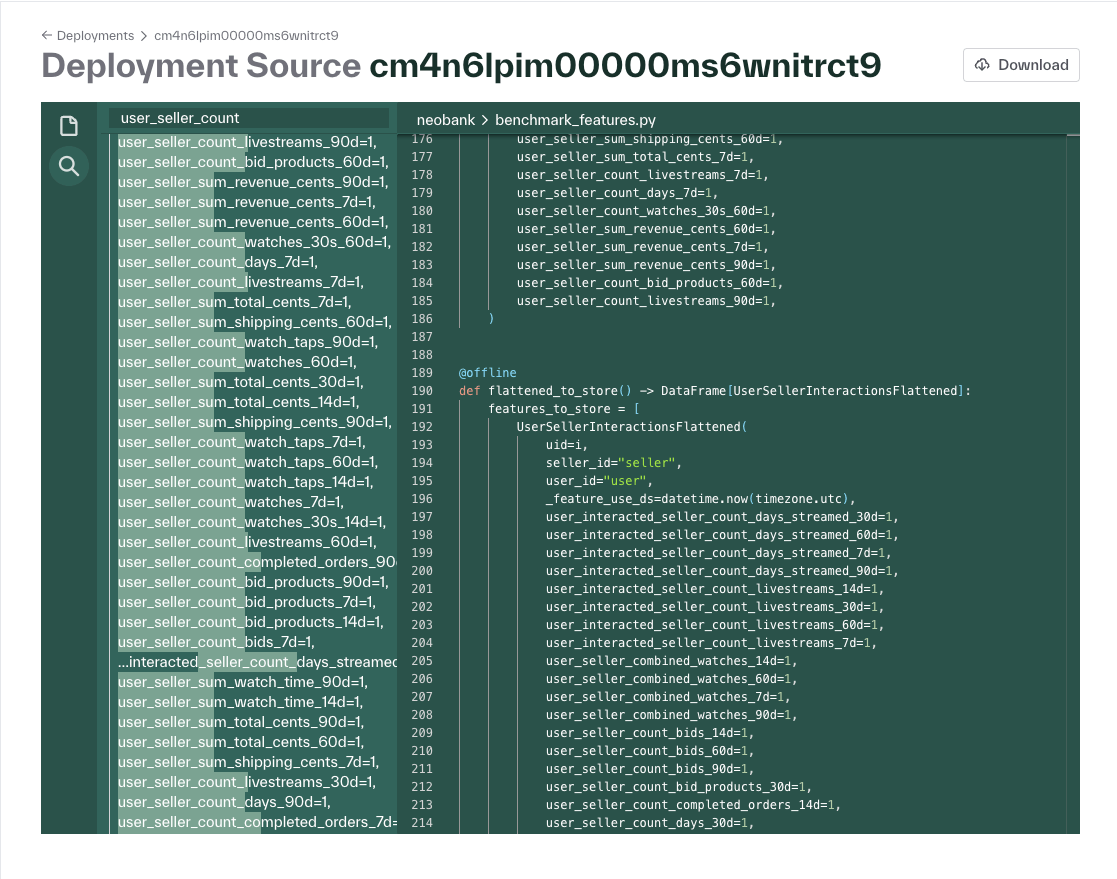
Dataset revision metadata get and set
DatasetRevision objects now have get_metadata and set_metadata methods to get and set metadata as a dictionary. This can be useful for storing information such as whether a dataset has been ingested to the online or offline store, or for tagging and labeling datasets. Read more about all of the DatasetRevision methods in our API documentation.
Expressions support more array functions
The chalk.functions library now supports more array functions that can be used in expressions. array_max and array_min return the maximum and minimum values in an array, respectively. array_distinct returns a list of the distinct elements in an array, and array_sort sorts the elements of an array by ascending or descending order. Read more about all of the chalk.functions available for writing expressions in our API docs.
December 9, 2024
Expressions support struct field access and more functions
You can now reference dataclass struct fields with expressions. We've also added more functions to chalk.functions that can be used in expressions, including is_us_federal_holiday for determining if a date is a federal holiday in the United States, array_sort for sorting the elements of an array by ascending or descending order, and element_at for retrieving the element at a specified index in an array. To read more about all of the chalk.functions in your toolbox for writing expressions, check out our API docs.
New overview page and dashboard updates for viewing stack traces and recent feature values
We've updated the overview page in the dashboard to show an overview of query activity and cluster health for your environment. You can now view graphs and metrics for online and offline queries, resolver runs, query latency, online store activity, deployments, incidents, errors, and connections. Please reach out to the Chalk team if you have any questions about any of these metrics
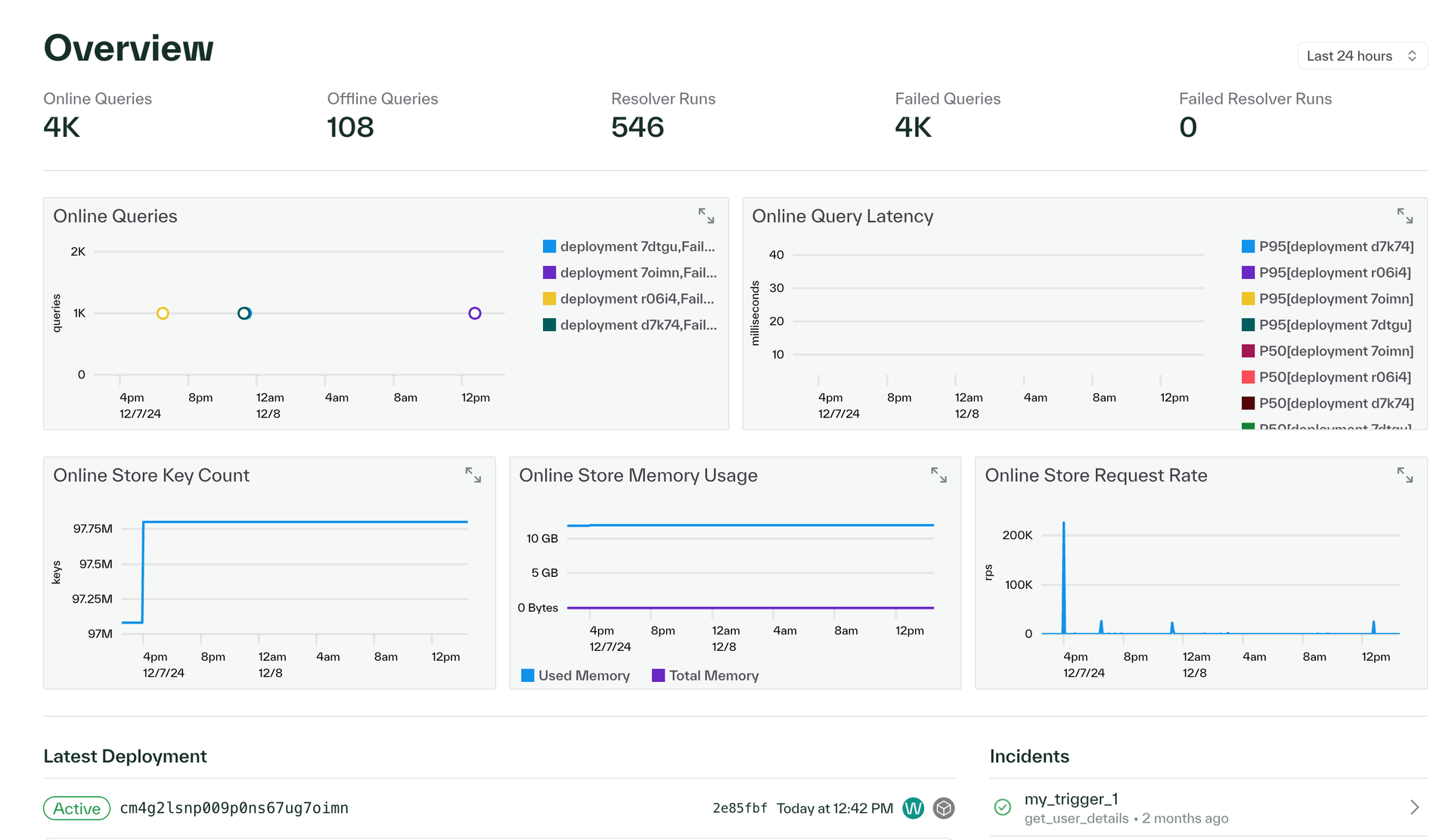
In addition, you can now view the latest stack trace for a pod in your cluster under Settings > Kubernetes, which can be helpful for debugging offline queries or scheduled runs.
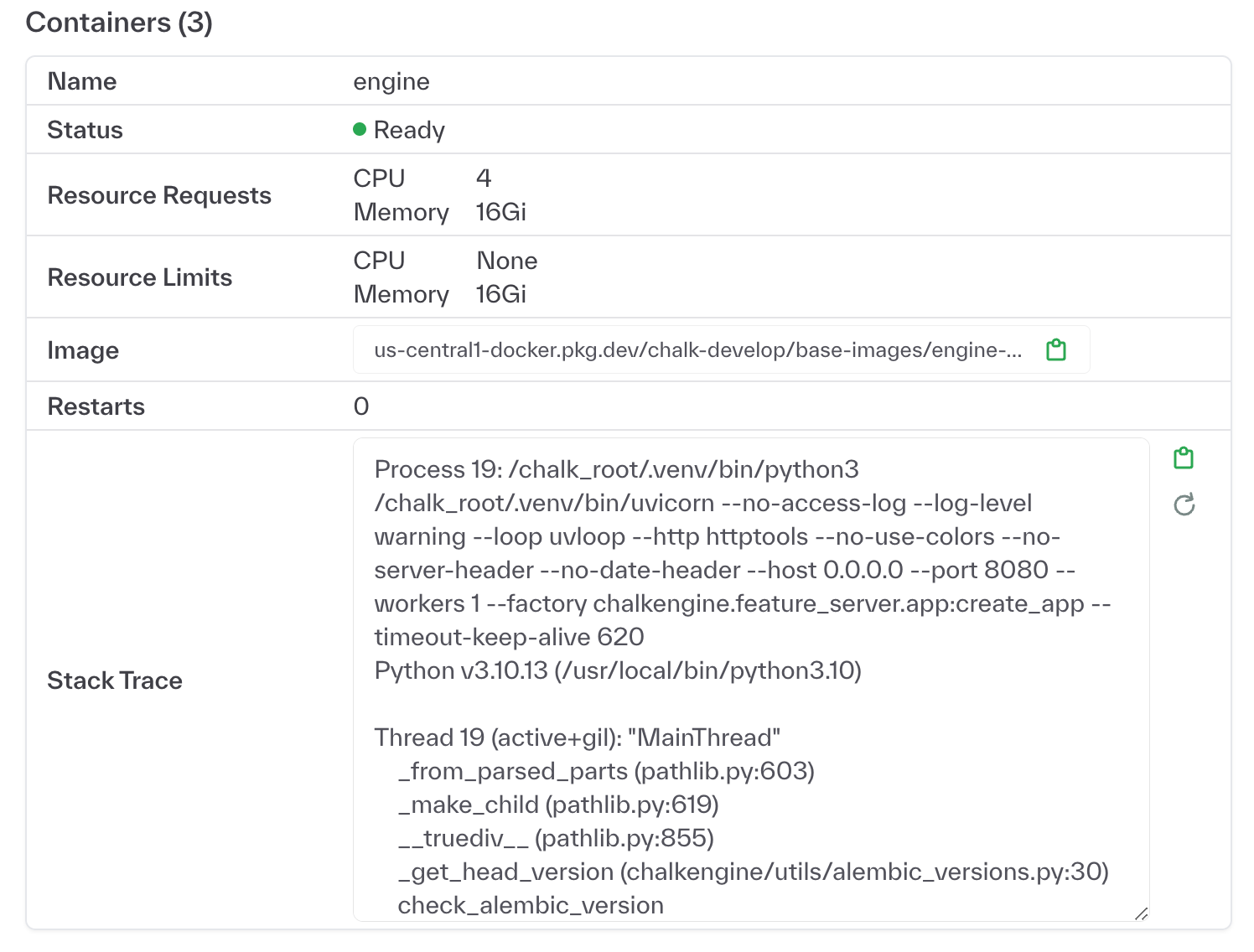
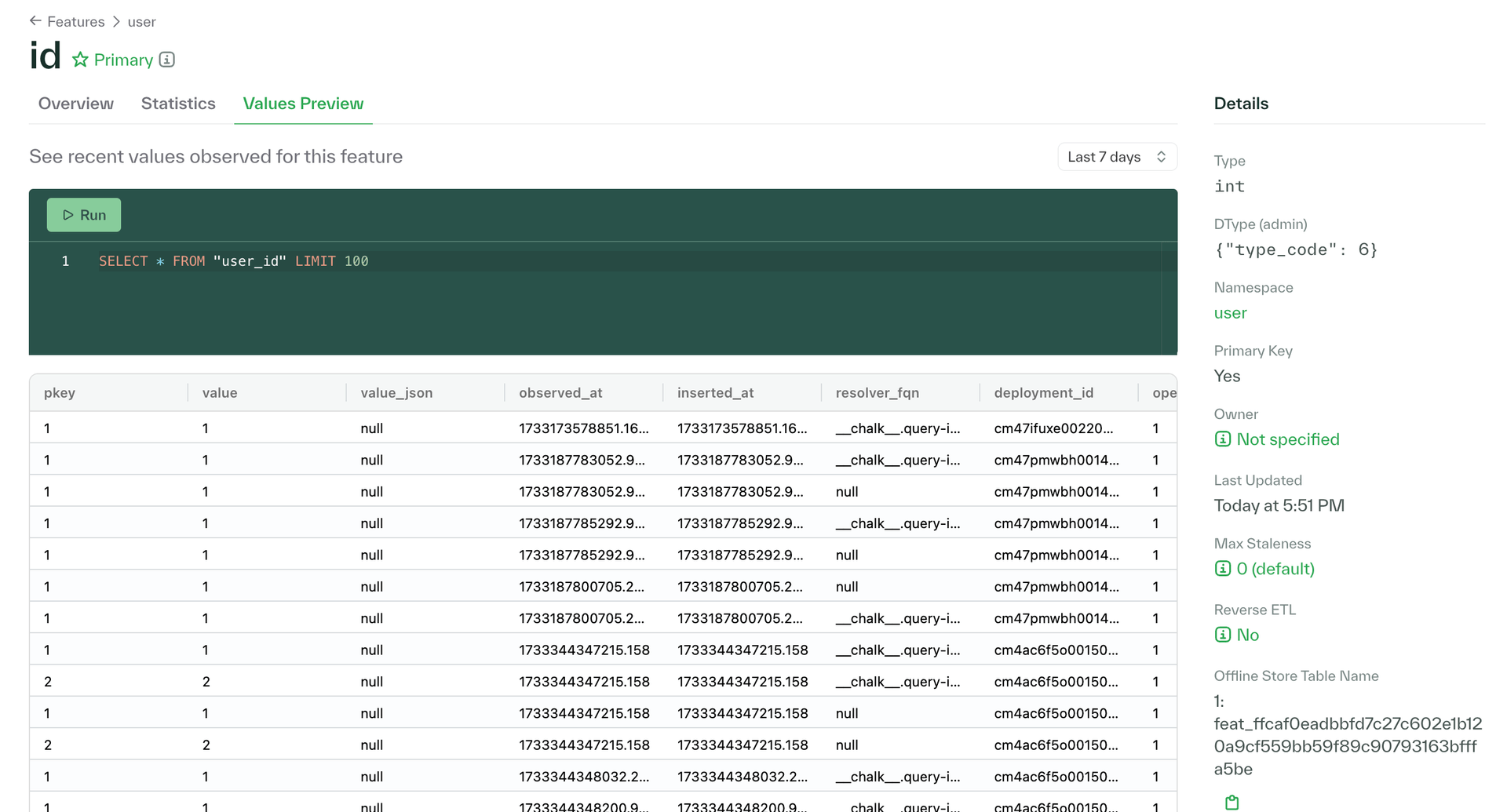
Customers with a gRPC engine can also use the new Values Preview tab on the Features page to view recently observed feature values as loaded from the offline store.
Postgres Native SQL driver improvements
The Postgres Native SQL driver now supports parameters, as well as returning relationships and scalar aggregations, expanding the kinds of SQL resolvers querying Postgres sources that we can support with performant C++ execution.
Read our updated documentation on windowed aggregations
We've updated our documentation on windowed aggregations to include more information on how to fuse real-time aggregations with materialized pre-aggregations for windowed features.
December 2, 2024
We now support Poetry for managing Python dependencies
You can now use Poetry to manage Python dependencies in your Chalk project. Simply set the requirements field in your chalk.yaml file to pyproject.toml to use Poetry for dependency management. Read more about how to use configuration files here.
project: no-fun-project-names
environments:
default:
runtime: 'python310'
requirements: pyproject.tomlExpressions now support more datetime, JSON, string, and math functions
We've added more functions to chalk.functions that can be used in expressions. You can now use json_extract_array to extract arrays of strings, bools, numbers, or nulls from a JSON feature, safe_divide to divide two numbers safely, returning None if the denominator is zero, to_iso8601 to convert a datetime feature to an ISO 8601 string, from_unix_seconds and from_unix_milliseconds to convert a Unix timestamp in seconds or milliseconds to a datetime feature, and finally regexp_replace to replace substrings in a string using a regular expression. To read more about all of the chalk.functions in your toolbox for writing expressions, check out our API docs.
Warning banners in dashboard for deployments
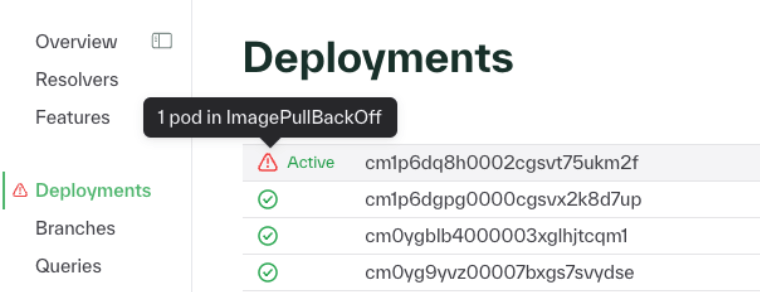
We've added warning banners in the dashboard to alert you to potential issues in your deployments, such as when pods fail to start up cleanly. These banners will help with monitoring and observability for deployment health.
November 25, 2024
Offline query now accepts parquet inputs and relative input times
Offline queries can now accept parquet files as input by passing in a ”s3://“ or ”gs://“ URL as the offline_query(input=“…”) parameter. In addition, you can now define upper and lower bounds for offline queries with a timedelta that is set relative to the min/max input times per shard. For example, you can now set offline_query(lower_bound=timedelta(days=-30) to set the lower bound to be 30 days before the earliest input_time or offline_query(upper_bound=timedelta(days=30) to set the upper bound to be 30 days after the latest input_time. To read more about offline query parameters, see our API docs.
Backfill materialized window aggregations over computed features
You can now define a materialized aggregate backfill over features that are returned by multiple resolvers rather than just one resolver. Read more about the chalk aggregate backfill command in our CLI docs.
Expressions now support more array and encoding functions
We've added more functions to chalk.functions that can be used in expressions. You can now use array_join to concatenate array elements into a string, cardinality to count the number of elements in an array, as well as max and min to find the maximum and minimum values, respectively, in an array. You can also use max_by and min_by to find the row with the maximum and minimum values in a given column in a DataFrame. For mathematical operations, you can now round numbers and use from_base for base conversion. For encoding, you can now compute the sha1, sha256, and sha512 hashes of strings. Finally, you can use format_datetime to format datetime features using a format string and strpos to find the first position of a substring in a string. To read more about all of the chalk.functions in your toolbox for writing expressions, check out our API docs.
Optionally cache nulls or default feature values in the online store
Where you could previously choose whether to cache null feature values in the online store, you can now use the cache_defaults parameter to optionally cache default feature values in the online store. Customers with DynamoDB or Redis online stores can also choose to evict_defaults from the online store, evicting the entry that would have been a default value from the online store if it exists. Read more about how to use cache_defaults and cache_nulls in our API docs.
Define features as map types
You can now define features as map types and reference these map features in expressions.
from chalk.features import features
@features
class User:
id: str
user_preferences: dict[str, bool] = {"Advertising cookies": True, "Functional cookies": True}Retrieve map types from DynamoDB data sources as either dicts or strings
You can now retrieve Map document types from DynamoDB data sources as either dicts or strings, using the new map feature type.
Dashboard updates for viewing Kubernetes logs
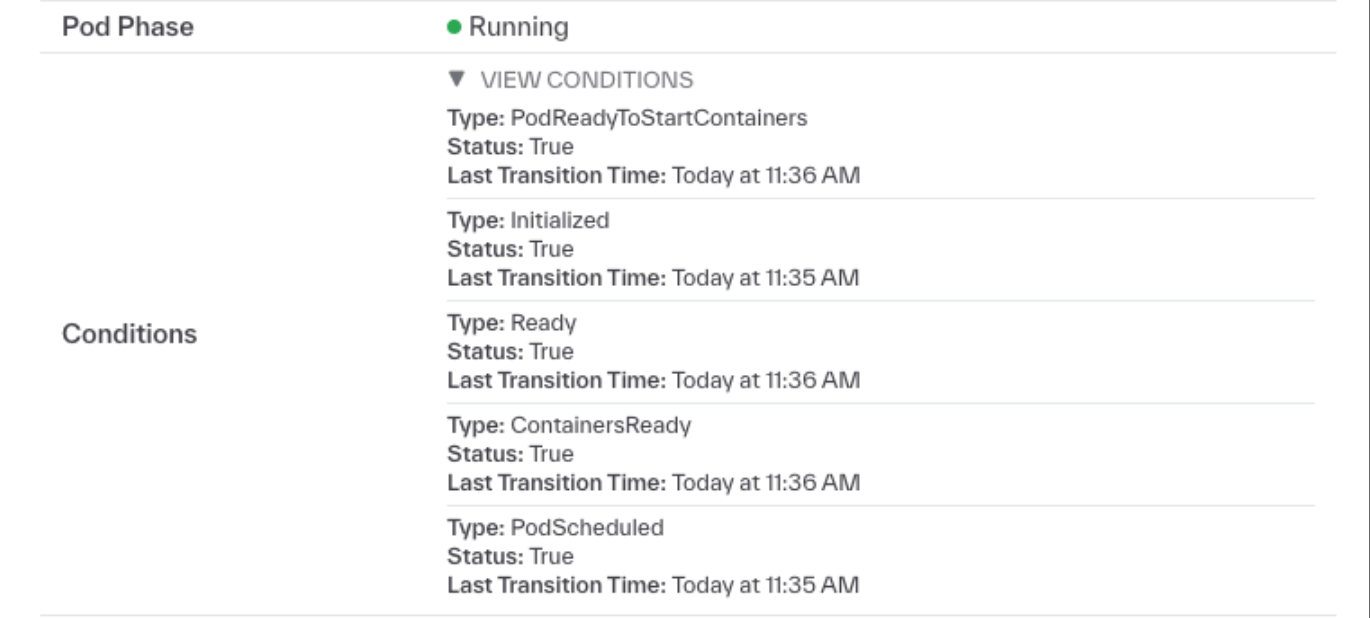
We’ve exposed much more granularity for Kubernetes logs in the dashboard. You can now filter logs by pod name, component, resource group, and deployment. These filters are set in the page query params, which means that you can send a link to pre-filtered log views. The links that are newly exposed in the Kubernetes pod view now directs to a pre-filtered logs viewer page. Finally, you can now view pod conditions in the Kubernetes pod view, which can include useful information for debugging failed or pending pods.
Improved stacktrace rendering in Chalk CLI
We've drastically improved the rendering of stacktraces in the Chalk CLI with improved syntax highlighting and clearer formatting to make debugging easier.
November 18, 2024
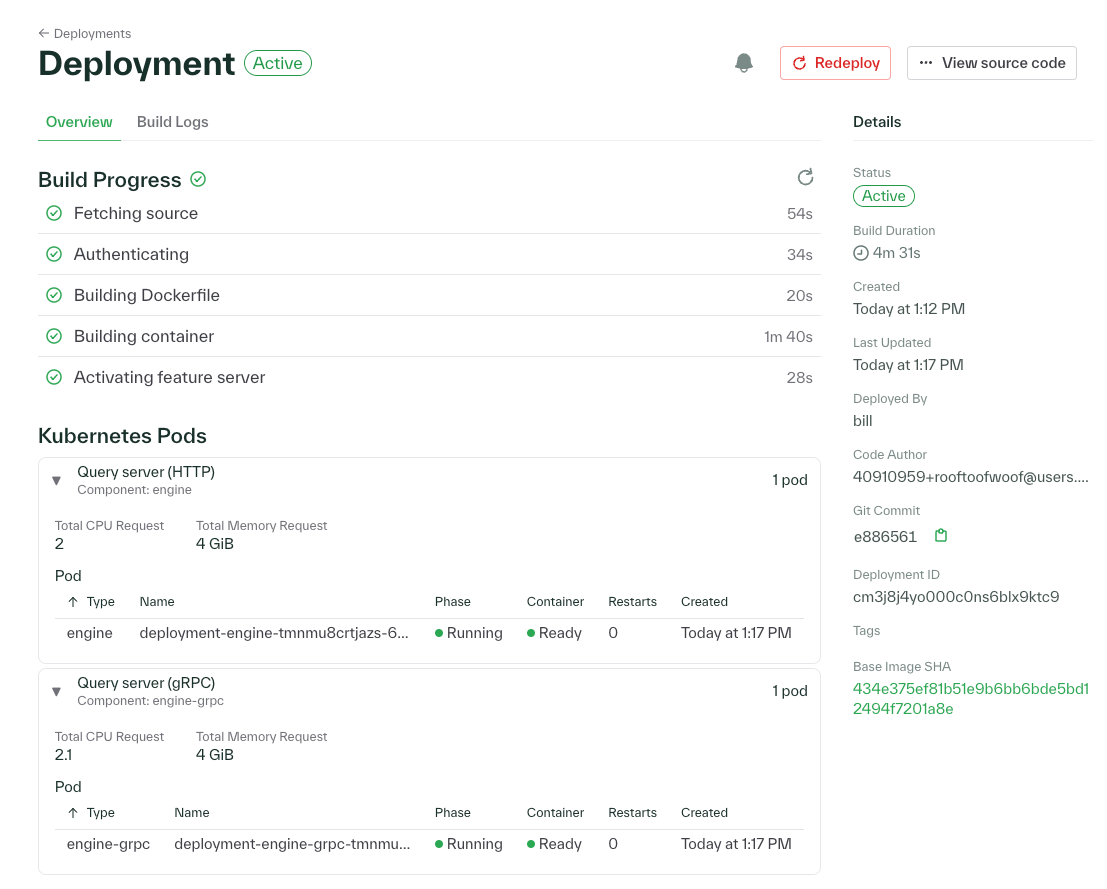
View Kubernetes resources created by each deployment in the dashboard
You can now view the Kubernetes pods created by each deployment in the dashboard along with additional details like the pod states and the resources requested by each pod.
Resolve list features with expressions
We've added the array_agg function to chalk.functions to help you resolve list features with underscore expressions. For example, you can now express the following features to aggregate all categories of videos watched for a user.
import chalk.functions as F
from chalk import DataFrame
from chalk.features import _, features
@features
class VideoInteraction:
id: str
video_url: str
video_category: str
user_id: "User.id"
@features
class User:
id: str
videos_watched: DataFrame[VideoInteraction]
all_watched_video_categories: list[str] = F.array_agg(_.videos[_.category])To see all of the chalk.functions that you can use in expressions, see our API documentation.
View usage information through the Chalk CLI
Users can now use the chalk usage commands to view usage information for their projects and environments. If you have any questions, please reach out to the Chalk team.
November 11, 2024
Idempotency in triggered resolver runs
We now provide an idempotency key parameter for triggering resolver runs so that you can ensure that only one job will be kicked off per idempotency key provided.
ChalkClient.check() function for easy integration testing
The ChalkClient now has a check function that enables you to run a query and check whether the query outputs match your expected outputs. This function should be used with pytest for integration testing. To read more about different methods and best practices for integration testing, see our integration test docs.
Expressions support more mathematical and logical functions
This week, we've added mathematical functions floor, ceil, and abs to chalk.functions, along with the logical functions when, then, otherwise, and is_null. We've also added the haversine function for computing the Haversine distance between two points on Earth given their latitude and longitude. These points can be used in expressions to define features with code that can be statically compiled in C++ for faster execution. See the full list of functions you can use in underscore expressions in our API docs.
Dashboard improvements for providing more insights into resolver performance and execution
In the dashboard, users can now view the P50, P75, P95, and P99 latencies for resolvers in the table under the Resolver tab of the menu. You can also customize which columns are displayed in the table by clicking the gear icon in the top left corner of the table.
In addition, we've added a SQL Explorer for examining resolver output for queries that are run with the store_plan_stages=True parameter.
chalk healthcheck in CLI
You can now use the chalk healthcheck command in the CLI to view information on the health of Chalk's API server and its services. The healthcheck provides information for the API server based on the active environment and project. To read more about the healthcheck command, see the CLI documentation.
November 4, 2024
Offline Query Specifications for shards and workers
When running an asynchronous offline query, you can now specify the inputs num_shards and num_workers as parameters to allow for more granular control over the parallelization of your query execution. To see all of the offline query options, check out the offline query documentation.
In addition, offline query progress reporting now specifies progress by shard, giving developers more insight into where their offline query is in the execution progress.
ChalkClient can now use the default Git branch
You can now default to using the name of your current Git branch when developing using the ChalkClient. For example, if you have checked out a branch named my-very-own-branch you can now set ChalkClient(branch=True) and all of your client calls will be directed at my-very-own-branch. To read more about how to use ChalkClient, see our API documentation.
Expressions support functions for URL parsing, regular expressions, and more
We've added more functions to chalk.functions that can be used in expressions. You can now use regexp_like, regexp_extract, split_part, and regexp_extract_all to do regular expression matching and use url_extract_host, url_extract_path, and url_extract_prtocol to parse URL's. In addition, we've added helpful logical functions like if_then_else, map_dict, and cast to broaden the span of features that you can define using expressions. To read more about all of our functions, check out our API documentation.
Deployment build logs for AWS environments
We now provide more detailed build logs for deployments in AWS environments in the dashboard!
October 28, 2024
Run predictions against SageMaker from Chalk, and do so much more in expressions
We've added a new function chalk.functions.sagemaker_predict that allows you to run predictions against a SageMaker endpoint to resolve features. Read more about how to define a SageMaker endpoint, encode your input data, and run predictions in our SageMaker tutorial.
In addition to being able to make SageMaker calls, expressions now support a variety of new functions. With these functions imported from chalk.functions, you can perform encoding, decoding, math, datetime manipulation, string manipulation, and more! For example, say you have a Transaction feature, where you make a SageMaker call to enrich the transaction data and provide a label for the transaction, and you parse this label for other features. You can now define all of these features related to transaction enrichment using expressions and Chalk functions in the feature definition:
from datetime import date
import chalk.functions as F
from chalk.features import _, features, Primary
@features
class Transaction:
id: str
amount: float
date: date
day: int = F.day_of_year(_.date)
month: int = F.month_of_year(_.date)
sagemaker_input_data: bytes = F.string_to_bytes(_.id, encoding="utf-8")
transaction_enrichment_label: bytes = F.sagemaker_predict(
_.sagemaker_input_data,
endpoint="transaction-enrichment-model_2.0.2024_10_28",
target_model="model_v2.tar.gz",
target_variant="production_variant_3"
)
transaction_enrichment_label_str: str = F.bytes_to_string(_.transaction_enrichment_label, encoding="utf-8")
is_rent: bool = F.like(_.transaction_enrichment_label_str, "%rent%")
is_purchase: bool = F.like(_.transaction_enrichment_label_str, "%purchase%")
Nested materialized windowed aggregation references!
You can now reference other windowed aggregations in your windowed aggregation expressions. To read more about how to define your windowed aggregations, see our example here.
Updated usage dashboard to view CPU and storage requests grouped by pod and namespace
We've updated the Usage Dashboard with a new view under the Pod Resources tab that allows you to view CPU and storage requests by pod as grouped by cluster, environment, namespace, and service! If you have any questions about the usage dashboard, please reach out to the Chalk team.
Dropping support for Python 3.8
From chalkpy==2.55.0, Chalk is dropping support for Python 3.8, which has reached end-of-life. If you are still using Python 3.8, please upgrade to Python 3.9 or higher.
October 21, 2024
Pub/Sub streaming source
We've enabled support for using Pub/Sub as a streaming source. Read more about how to use Pub/Sub as a streaming source here.
Online/Offline Storage for Offline Queries
You can automatically load offline query outputs to the online and offline store using the boolean parameters store_online and store_offline. Below is an example of how to use these parameters.
from chalk.client import ChalkClient
client = ChalkClient()
ds = client.offline_query(
input={"user.id": [1, 2, 3, 4, 5]},
output=["user.num_interactions_l7d", "user.num_interactions_l30d", "user.num_interactions_l90d"],
store_online=True,
store_offline=True
)SQL explorer for query outputs in the dashboard
Customers running gRPC servers can now run SQL queries on the dataset outputs of online and offline queries in the dashboard. To enable this feature for your deployment, please reach out to the team.
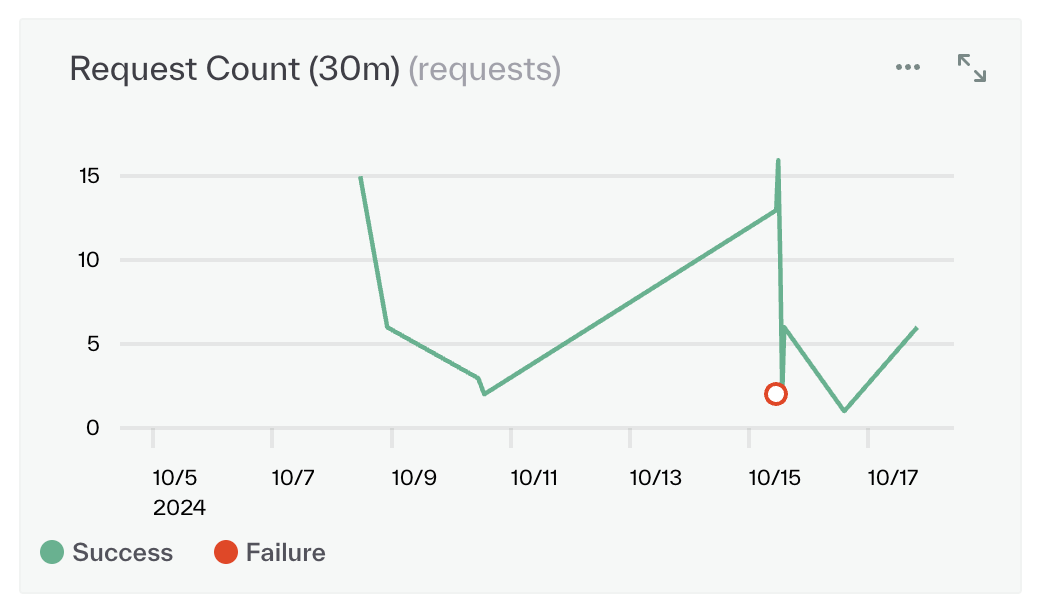
Color updates in the dashboard
We've updated our color scheme in the dashboard to more clearly differentiate between successes and failures in metrics graphs!
October 14, 2024
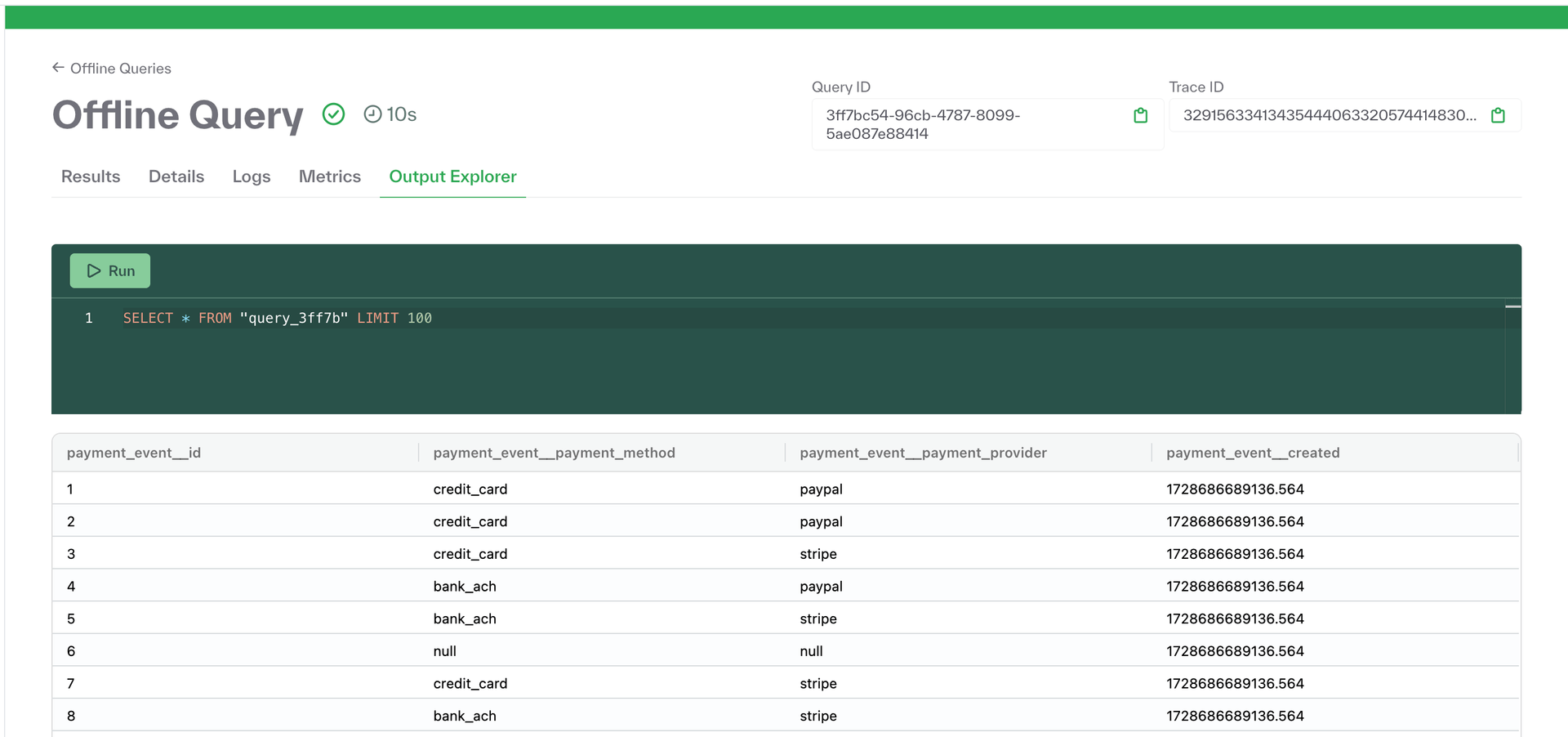
SQL explorer in dashboard for datasets
Customers can now run SQL queries on dataset outputs in the dashboard. To use this feature, navigate to the Datasets page in the menu, select a dataset, and click on the Output Explorer tab.
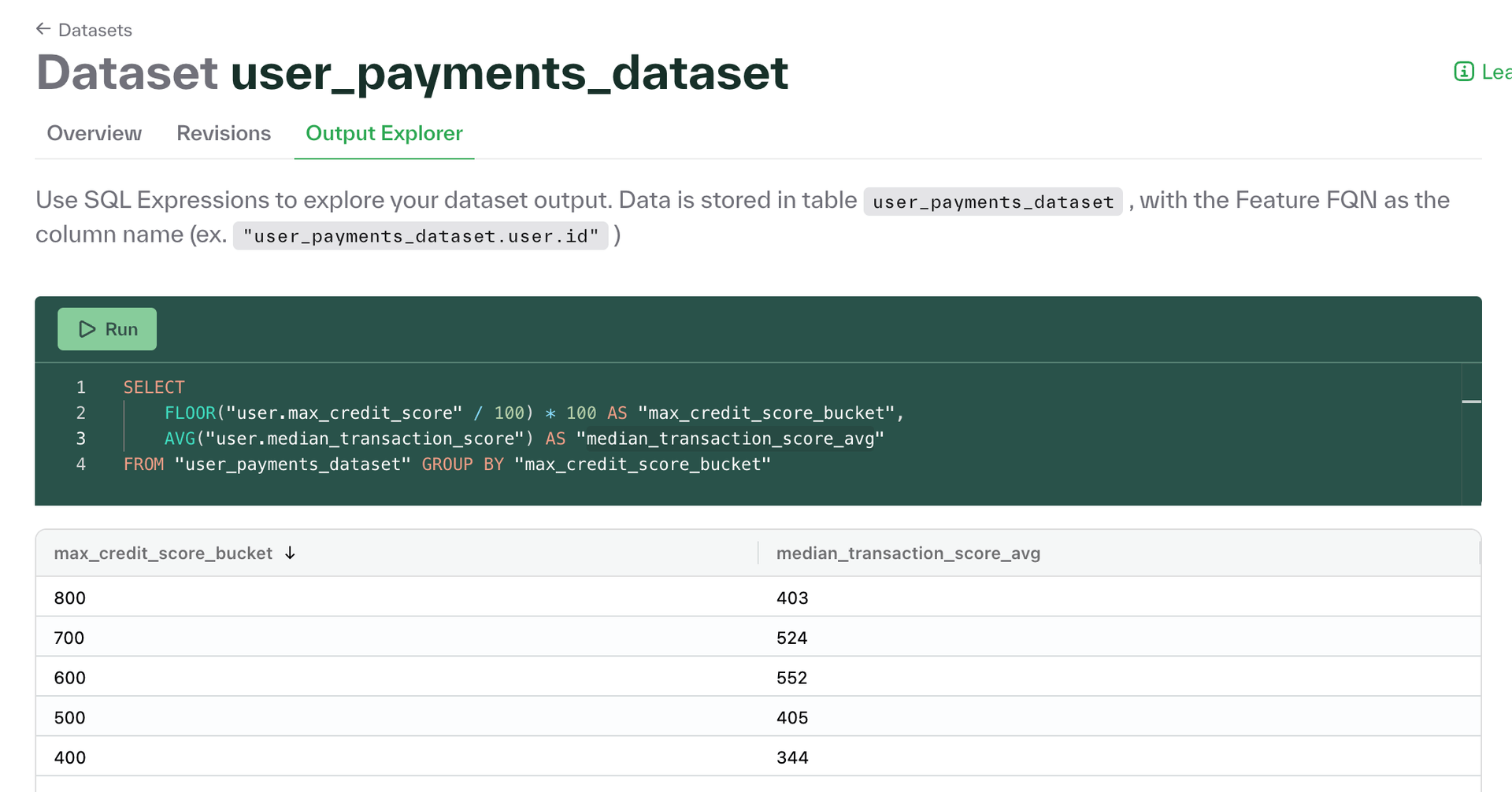
Optionally evict nulls from your DynamoDB online store
Last week we enabled the option to decide whether to persist null values for features in Redis lightning online stores, and this week we have enabled this feature in DynamoDB online stores. By default, null values are persisted in the online store for features defined as Optional, but you can set cache_nulls=False in the feature method to evict null values. Read more about how to use the cache_nulls parameter here.
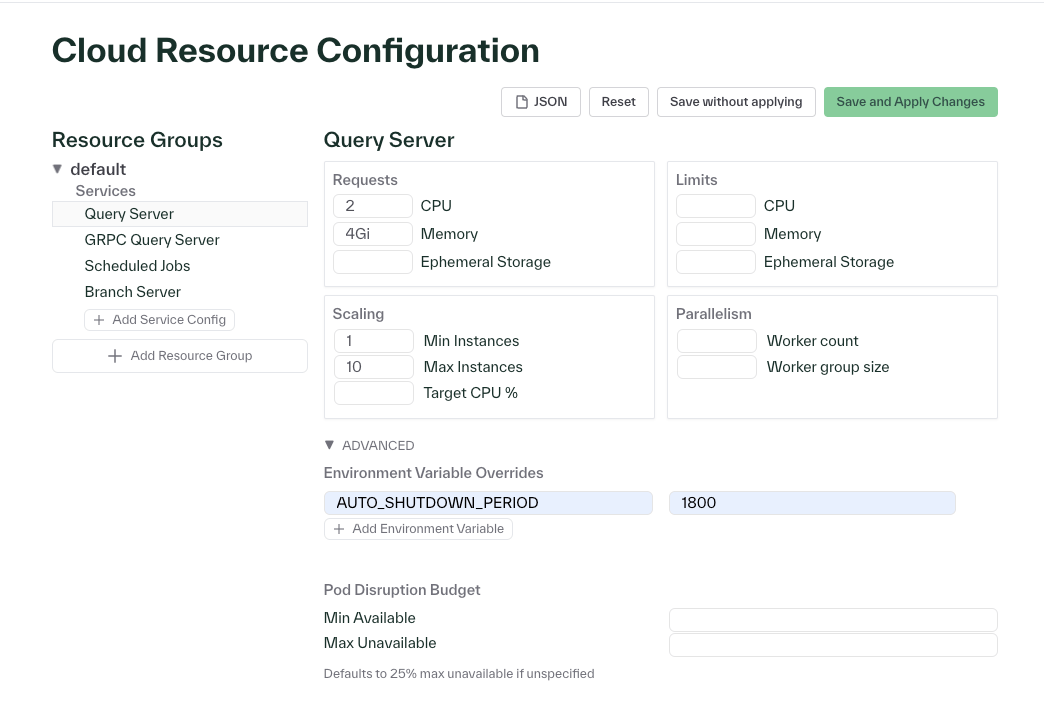
Set environment variables and more in the Advanced section of the Cloud Resource Configurations page in the dashboard
You can set cloud resource configurations for your environment by navigating to Settings > Resources in the dashboard. In addition to specifying resource configurations for resource groups like instance counts and CPU, you can now also set environment variables and other settings like Kubernetes Node Selectors. The Kubernetes Node Selector enables you to specify the machine family you would like to use for your deployment. For example, this would map to EC2 Instance Types for AWS deployments or Compute Engine Machine Families for GCP deployments. If you have any questions about how to use any of these settings in the configuration page, please reach out to the team.
October 7, 2024
Expressions support datetime subtraction and total_seconds
Expressions now support datetime subtraction and the use of a new library function chalk.functions.total_seconds. This allows you to compute the number of seconds in a time duration and define more complex time interval calculations using performant underscore expressions.
For example, to define a feature that computes the difference between two date features in days and weeks, we can use chalk.functions.total_seconds and underscore date expressions together.
from chalk.functions as F
from chalk.features import _, features, Primary
from datetime import date
@features
class User:
id: str
created_at: date
last_activity: date
days_since_last_activity: float = F.total_seconds(date.today() - _.last_activity) / (60 * 60 * 24)
num_weeks_active: float = F.total_seconds(_.last_activity - _.created_at) / (60 * 60 * 24 * 7)Optionally evict nulls from your Redis lightning online store
You can now select whether to persist null values for features in the Redis lightning online store using the cache_nulls parameter in the feature method. By default, null values are persisted in the online store for features defined as Optional. If you set cache_nulls=False, null values will not be persisted in the online store.
from chalk import feature
from chalk.features import features, Primary, Optional
@features
class RestaurantRating:
id: str
cleanliness_score: Optional[float] = feature(cache_nulls=False) # null values will not be persisted
service_score: Optional[float] = feature(cache_nulls=True) # null values will be persisted. This is the default behavior.
overall_score: float # null values are not persisted for required featuresFeature value metrics from gRPC server and feature table updates
Customers running the gRPC server can now reach out to enable feature value metrics. Feature value metrics include the number of observations, number of unique values, and percentage of null values over all queries, as well as the running average and maximum of features observed. Please reach out if you'd like to enable feature value metrics.
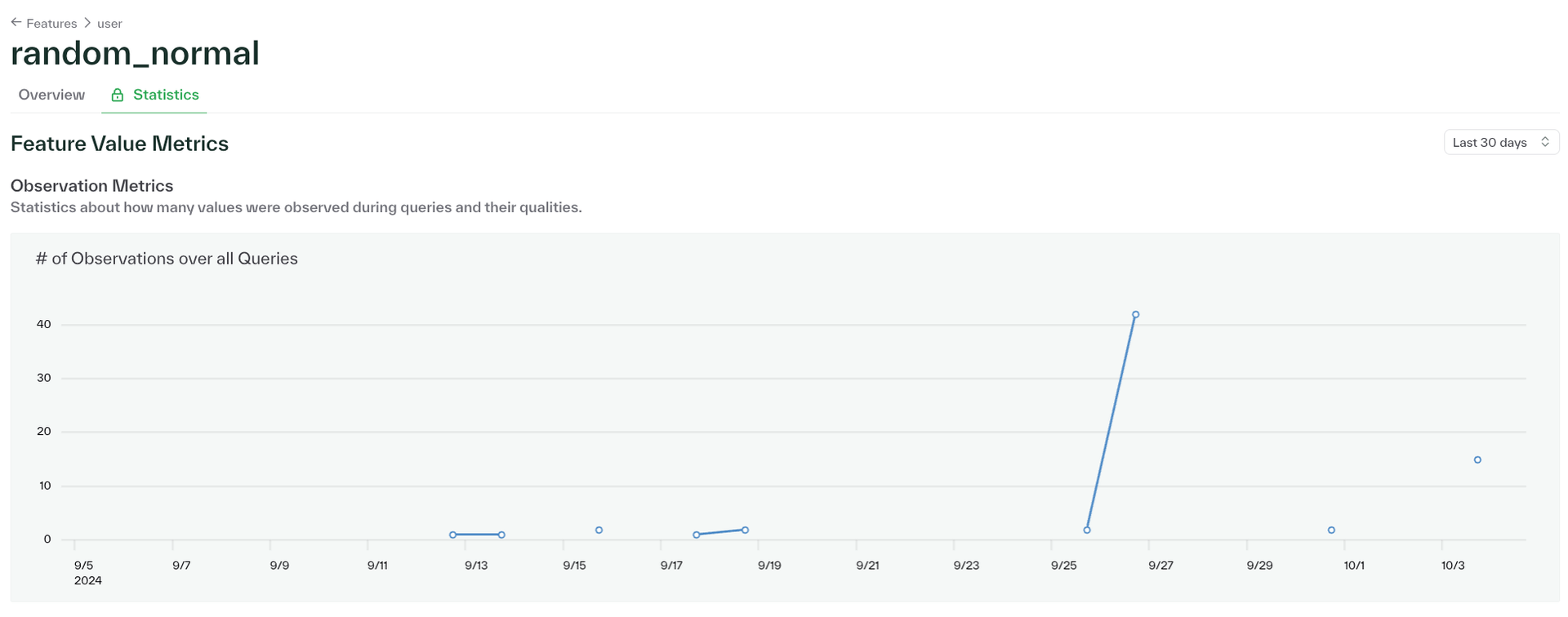
Additionally, the feature table in the dashboard has been updated to allow for customization of columns displayed, which enables viewing request counts over multiple time ranges in the same view.
September 30, 2024
Compute cosine similarity between two vector features
chalk.functions now offers a cosine_similarity function:
import chalk.functions as F
from chalk.features import _, embedding, features
@features
class Shopper:
id: str
preferences_embedding: Vector[1536]
@features
class Product:
id: str
description_embedding: Vector[1536]
@features
class ShopperProduct:
id: str
shopper_id: Shopper.id
shopper: Shopper
product_id: Product.id
product: Product
+ similarity: float = F.cosine_similarity(_.shopper.preferences_embedding, _.product.description_embedding)Cosine similarity is useful when handling vector embeddings, which are often used when analyzing unstructured text. You can also use embedding to compute vector embeddings with Chalk.
Dashboard now shows metrics for offline query runs
When looking at an offline query run in the dashboard, you'll now find a new Metrics tab showing query metadata, CPU utilization, and memory utilization.
Configuration option for recomputing features on cache misses
We have a new offline query configuration option for recomputing features _only_ when they are not already available in the offline store. This option is useful for workloads with computationally expensive features that cannot easily be recomputed. Please reach out if you'd like to try this feature.
September 23, 2024
Configurable retry policy for SQL resolvers
Sometimes, a SQL resolver may fail to retrieve data due to temporary unavailability. We've added new options for configuring the number of retry attempts a resolver may make (and how long it should wait between attempts). If you're interested in trying out this new functionality early, please let the team know.
Has-one join keys can be chained
When creating has-one relationships, you can set the primary key of the child feature class to the primary key of the parent feature class. For example, you may model an InsurancePolicy feature class as belonging to exactly one user by setting InsurancePolicy.id's type to Primary[User.id].
Now, we've updated Chalk so that you can chain more of these relationships together. For example, an InsurancePolicy feature class may have an associated InsuranceApplication. The InsuranceApplication may also have an associated CreditReport. Chalk now allows chaining an arbitrary number of has-one relationships. Chalk will also validate these relationships to ensure there are no circular dependencies.
Here's an example where we have features describing a system where user has one insurance policy, each policy has one submitted application, and each application has one credit report:
from chalk import Primary
from chalk.features import features
@features
class User:
id: str
# :tags: pii
ssn: str
policy: "InsurancePolicy"
@features
class InsurancePolicy:
id: Primary[User.id]
user: User
application: "InsuranceApplication"
@features
class InsuranceApplication:
id: Primary[InsurancePolicy.id]
stated_income: float
# For the sake of illustrating has-one relationships,
# we're assuming exactly one credit report per
# application, which may not be realistic. A has-many
# relationship may be more accurate here.
credit_report: "CreditReport"
@features
class CreditReport:
id: Primary[InsuranceApplication.id]
fico_score: int
application: InsuranceApplicationTo query for a user's credit report, you would write:
client.query(
inputs={User.id: "123"},
output=[User.policy.application.credit_report],
)To write a resolver for one of the dependent feature classes here, such as CreditReport.fico_score, you would still reference the relevant feature class by itself:
@online
def get_fico_score(id: CreditReport.id) -> CreditReport.fico_score:
...As an aside, if your resolver depends on features from other feature classes, such as User.ssn, we instead recommend joining those two feature classes directly for clarity (which was possible prior to this changelog entry):
from chalk import Primary
from chalk.features import features
from chalk.features import features, has_one
@features
class User:
id: str
# :tags: pii
ssn: str
policy: "InsurancePolicy"
credit_report: "CreditReport" = has_one(lambda: User.id == CreditReport.id)
# ... the rest of the feature classes
@online
def get_fico_score(id: User.id, ssn: User.ssn) -> User.credit_report.fico_score:
...User permissions page shows roles per user
When you view Users in the Chalk settings page, you will now find a menu for viewing the roles associated with each user, whether those roles are granted directly or via SCIM.
September 16, 2024
New feature and resolver UI in the dashboard
We have shipped a new UI for the Features and Resolvers sections of the dashboard!
The new UI has tables with compact filtering and expanded functionality. You can now filter and sort by various resolver and feature attributes! The tables also provide column resizing for convenient exploration of the feature catalog.
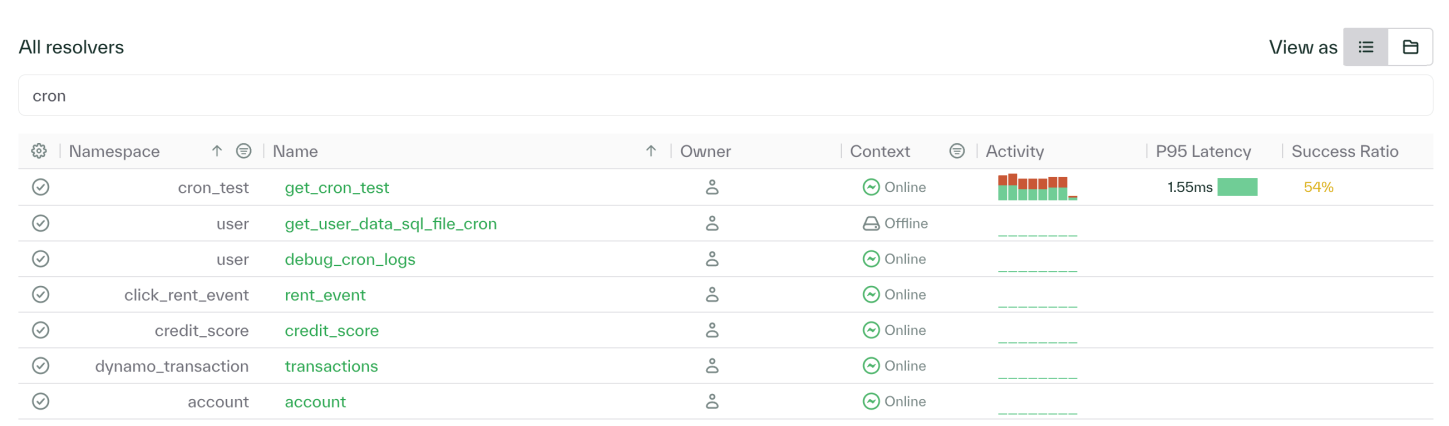
The features table now includes request counts from the last 5 minutes up to the last 180 days, has built-in sorting, and has a Features as CSV button to download all the feature attributes in your table as a CSV for further analysis.

New helper functions for feature computation
The new chalk.functions module contains several helper functions for feature computation. For example, if you have a feature representing a raw value in GZIP-compressed value, you can use gunzip with an underscore reference to create an unzipped feature. The full list of available functions can be found in our expression documentation.
JSON feature type
You can now define features with JSON as the type after importing JSON from the chalk module. You can then reference the JSON feature in resolver and query definitions. You can also retrieve scalar values from JSON features using the json_value function.
September 9, 2024
Configure Chalk to not cache null feature values
By default, Chalk caches all feature values, including null. To prevent Chalk from caching null values, use the feature method and set cache_nulls to False.
More static execution of certain Python resolvers
We built a way to statically interpret Python resolvers to identify ones that are eligible for C++ execution, which has faster performance. For now, resolvers are eligible if they do simple arithmetic and logical expressions. If you're interested in learning more and seeing whether these new query planner options would apply to your codebase, please reach out!
New tutorial for using Chalk with SageMaker
We have a new tutorial for using Chalk with SageMaker available now. In the tutorial, we show how to use Chalk to generate training datasets from within a SageMaker pipeline for model training and evaluation.
September 3, 2024
Feature catalog shows associated named queries
In the August 19 changelog entry, we announced NamedQuery, a tool for naming your queries so that you can execute them without writing out the full query definition.
This week, we've updated the dashboard's feature catalog so that it shows which named queries reference a given feature as input or output.

August 26, 2024
View aggregation backfills in the dashboard
We added a new Aggregations page to the dashboard where you can see the results of aggregate backfill commands. Check it out to see what resolvers were run for a backfill, the backfill's status, and other details that will help you drill down to investigate performance.
For more details on aggregate backfills, see our documentation on managing windowed aggregations.
August 19, 2024
Execute queries by name
Instead of writing out the full definition of your query each time you want to run it, you can now register a name for your query and reference it by the name!
Here's an example of a NamedQuery:
from chalk import NamedQuery
from src.feature_sets import Book, Author
NamedQuery(
name="book_key_information",
input=[Book.id],
output=[
Book.id,
Book.title,
Book.author.name,
Book.year,
Book.short_description
],
tags=["team:analytics"],
staleness={
Book.short_description: "0s"
},
owner="mary.shelley@aol.com",
description=(
"Return a condensed view of a book, including its title, author, "
"year, and short description."
)
)After applying this code, you can execute this query by its name:
chalk query --in book.id=1 --query-name book_key_informationTo see all named queries defined in your current active deployment, use chalk named-query list.
As Shakespeare once wrote, "What's in a named query? That which we call a query by any other name would execute just as quickly."
Miscellaneous improvements
- The offline query page of the dashboard now shows which table in your offline store contains the query's output values.
August 12, 2024
Queries can reference multiple feature namespaces
Previously, you could only reference one feature namespace in your queries. Now you can request features from multiple feature namespaces. For example, here's a query for a specific customer and merchant:
client.query(
input={
Customer.id: 12345,
Merchant.id: 98765,
},
output=[Customer, Merchant],
)Dashboard resources view shows allocatable CPU and memory
The resources page of the dashboard now shows the allocatable and total CPU and memory for each of your Kubernetes nodes. Kubernetes reserves some of each machine's resources for internal usage, so you cannot allocate 100% of a machine's stated resources to your system. Now, you can use the allocatable CPU and memory numbers to tune your resource usage with more accuracy.
Performance improvements
We identified an improvement for our query planner’s handling of temporal joins! Our logic for finding the most recent observation for a requested timestamp is now more efficient. Happy time traveling!
August 5, 2024
DynamoDB with PartiQL
We now support DynamoDB as a native accelerated data source! After connecting your AWS credentials, Chalk automatically has access to your DynamoDB instance, which you can query with PartiQL.
Expressions support references to the target window duration
Expressions on windowed features can now include the special expression _.chalk_window to reference the target window duration. Use _.chalk_window in windowed aggregation expressions to define aggregations across multiple window sizes at once:
@features
class Transaction:
id: int
user_id: "User.id"
amount: float
@features
class User:
id: int
transactions: DataFrame[Transaction]
total_spend: Windowed[float] = windowed(
"30d", "60d", "90d",
default=0,
expression=_.transactions[_.amount, _.ts > _.chalk_window].sum(),
materialization={"bucket_duration": "1d"},
)Offline queries allow resource overriding
offline_querynow supports theresourcesparameter.resources
allows you to override the default resource requests associated with offline queries and cron jobs so that you can control CPU, memory, ephemeral volume size, and ephemeral storage.
July 26, 2024
Dashboard improvements
- The offline query page of the dashboard now shows live query progress. After query completion, the query page will
also show how long each resolver took to run."
- The Kubernetes resource page in the dashboard shows which kinds of hardware resources are currently running. It also
allows you to group resources by application, component, and other common groupings.
July 19, 2024
Datasets and dataset revisions now support previews and summaries
Datasets and DatasetRevisions have two new methods: preview and summary. preview shows the first few rows of the query output. summary shows summary statistics of the query output. Here's an example of summary output:
describe user.id ... __index__ shard_id batch_id
0 count 1.0 ... 1.0 0 0
1 null_count 0.0 ... 0.0 0 0
2 mean 1.0 ... 0.0 0 0
3 std 0.0 ... 0.0 0 0
4 min 1.0 ... 0.0 0 0
5 max 1.0 ... 0.0 0 0
6 median 1.0 ... 0.0 0 0
[7 rows x 14 columns]Create isolated node pools for your resource groups (in AWS)
Chalk resource groups create separate independent deployments of the query server to prevent resource contention. For example, one team may want to make long-running analytics queries and another may want to make low-latency queries in line with customer requests.
We have updated the Cloud Resource Configuration page! You can now configure resource groups to use completely independent node pools to ensure your workflows run on separate computer hardware. The configuration page also allows you to specify exactly what kind of hardware will be available in each resource group so you can optimize the balance between cost and performance.
This feature is currently available for customers running Chalk in EKS, but will be available soon for customers using GKE.
Performance improvements
- We've significantly improved SQL runtime in our query planner by executing eligible queries in C++ instead of
SQLAlchemy. Chat with our support team if you'd like to update your query planner options.
- We improved the performance of some expressions by executing
count()operations as native dataframe
operations.
Miscellaneous improvements
- Our feature catalog now lets you filter features by their context (online or offline). Additionally, you can now search
features by their name, description, and owner.
- We fixed an issue where some underscore expressions had incorrect typechecking.
July 10, 2024
Feature catalog
You can now view and filter features in the feature catalog by their tags and owners.

July 1, 2024
Chalk gRPC
We shipped a gRPC engine for Chalk that improved performance by at least 2x through improved data serialization, efficient data transfer, and a migration to our C++ server. You can now use ChalkGRPCClient to run queries with the gRPC engine and fetch enriched metadata about your feature classes and resolvers through the get_graph method.
Spine SQL query
With ChalkPy v2.38.8 or later, you can now pass spine_sql_query to offline queries. The resulting rows of the SQL query will be used as input to the offline query. Chalk will compute an efficient query plan to retrieve your SQL data without requiring you to load the data and transform it into input before sending it back to Chalk. For more details, check out our documentation.
Static planning of expressions
We shipped static planning of expressions. expressions enable you to define and resolve features from operations on other features. When you use expressions, we now do static analysis of your feature definition to transform it into performant C++ code.
Expressions currently support basic arithmetic and logical operations, and we continue to build out more functionality! See the code snippet below for some examples of how to use expressions:
@features
class SampleFeatureSet:
id: int
feature_1: int
feature_2: int
feature_1_2_sum: int = _.feature_1 + _.feature_2
feature_1_2_diff: int = _.feature_1 - _.feature_2
feature_1_2_equality: bool = _.feature_1 == _.feature_2June 28, 2024
Chalk deployment tags
You can now add tags to your deployments. Tags must be unique to each of your environments. If you add an already existing tag to a new deployment, Chalk will remove the tag from your old deployment.
Tags can be added with the --deployment-tag flag in the Chalk CLI:
chalk apply --deployment-tag=latest --deployment-tag=v1.0.4Resource configuration management in dashboard
We updated our UI for resource configuration management in the dashboard! You can now toggle your view between a GUI or a JSON editor. The GUI exposes all the configuration options available in the JSON editor, including values that aren't set, and allows you to easily adjust your cluster's resources to fit your needs.
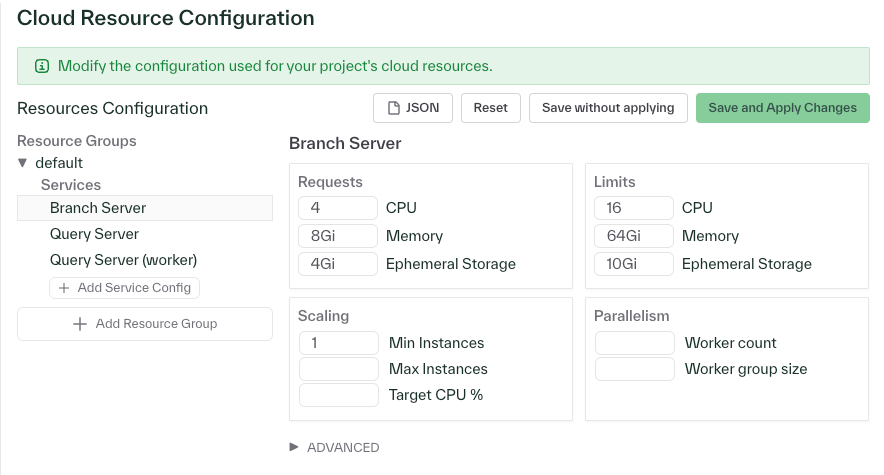
June 19, 2024
New data sources and native drivers
We added integrations for Trino and Spanner as new data sources. We've also added native drivers for Postgres and Spanner, which drastically improves performance for these data sources.
May 29, 2024
Heartbeating
We now have heartbeating to poll the status of long-running queries and resolvers, which will now mark any hanging runs that are no longer detected as "failed" after a certain period of time.
May 14, 2024
Data source and feature-level RBAC
We expanded the functionality of our service tokens to enable role-based access control (RBAC) at both the data source and feature level. On the datasource level, you can now restrict a token to only access data sources with matching tags to resolve features. On the feature level, you can restrict a token's access to tagged features either by blocking the token from returning tagged features in any queries but allowing the feature values to be used in the computation of other features, or by blocking the token from accessing tagged features entirely.

May 8, 2024
Incremental Status
We shipped statuses during incremental runs such that users can get a signal of the current high water mark of data being updated.
chalk incremental status --scheduled_query get_some_data__daily
✓ Fetched resolver progress state
Resolver: N/A
Query: run_this_query_daily
Environment: chalk12345
Max Ingested Timestamp: 2024-07-01T16:01:46+00:00
Last Execution Timestamp: 2024-07-01T00:01:27.421873+00:00April 18, 2024
Miscellaneous improvements
- Windowed resolvers have expanded to allow for hourly cadences.
April 9, 2024
Miscellaneous improvements
- SQL resolvers have improved error reporting for failures related to type conversion (e.g., if your resolver selects
an int column, but the feature's type is string)
March 29, 2024
Miscellaneous improvements
- SQL file resolvers have spellcheck (based on Levenshtein distance)
- Failed annotation parsing raises a type error with a more helpful error message
March 19, 2024
Scheduled Queries
Chalk now supports executing an offline_query on a schedule. Effectively, this extends the existing "scheduled resolver" functionality and allows you to execute more complicated data ingestion or caching workflows without needing to use Airflow or other external schedulers to orchestrate resolver execution.
Here's an example of a scheduled query that caches the number of transactions a user has made in the last 24 hours into the online store:
from chalk import ScheduledQuery
ScheduledQuery(
name="num_transactions_last_24h",
output=[User.num_transactions_last_24h],
schedule="0 0 * * *", # every day at midnight
store_online=True, # store the result in the online store
store_offline=False, # don't store this value in the offline store
)[//]: # 'Read more at Schedule Query.'
Bugfixes and improvements
offline_query(...)now acceptssample_features: list[Feature]as an argument. This works in conjunction
with recompute_features, and allows you to write something like:
ChalkClient().offline_query(
input={User.id: [...]},
output=[User.full_name],
recompute_features=True, # means "recompute all features
sample_features=[User.first_name, User.last_name] # but sample these features from the offline store
)This is useful when you have a large number of features that you want to recompute, but only a few that you want to sample.
ChalkClient.offline_querynow acceptsrun_asynchronously: boolto explicitly opt a query into running on an isolated worker.DataSet.to_polars()/.to_pandas()now acceptoutput_ts: strandoutput_id: strto customize the name of the timestamp and id columns in the output dataframe.- Feature and resolver discovery during
chalk applyis roughly twice as fast as ofchalkpy v2.33.9. - Dataset downloads no longer have any dependency on locally registered features, which resolves crashes for certain dataset management workflows.
ChalkClient.querynow supportsrequest_timeout: float, which is passed to the underlyingrequests.requestcall.
March 8, 2024
Bugfixes and improvements
- A persistent issue with
chalk drophas been resolved. Now,chalk dropwill allow you to reset a feature whose deletion has been deployed to the active deployment, which will allow you to re-deploy the feature. Previously, it was possible to get into a state that was impossible to recover from without support. tags(...)allows you to extract thetagsof a@featuresclass or a property (Feature) of that class.DataSet.to_polars()/to_pandas()now raises an error if the dataset computation had errors. This prevents the user from accidentally using a dataset that was not computed correctly. If you wish to use the dataset anyway, you can useDataSet.to_polars(ignore_errors=True).
March 1, 2024
Support for custom SQL sampling in offline query
You can now specify a custom SQL sampling query for offline queries. This allows you to use a native SQL query to compute the query's entity spine for offline queries. This is useful when you have a complicated sampling policy (i.e. class-based sampling). Additional non-primary key features can be provided as well.
January 22, 2024
required_resolver_tags for queries
You can now specify required_resolver_tags when querying. This allows you to ensure that a query only considers a resolver if it has a certain tag. This is useful for guaranteeing that a query only uses resolvers that are cost-efficient, or for enforcing certain compliance workflows.
In this example:
@offline()
def fetch_credit_scores() -> DataFrame[User.id, User.credit_score]:
"""
Call bureaus to get credit scores; costs money for each record retrieved.
"""
return requests.post(...)
@offline(tags=["low-cost"])
def fetch_previously_ingested_credit_scores() -> DataFrame[User.id, User.credit_score]:
"""
Pull previously retrieved credit scores from Snowflake only
"""
return snowflake.query_string("select user_id as id, credit_score from ...").all()querying with required_resolver_tags can be used to enforce that only 'low-cost' resolvers are executed --
# This query is guaranteed to /never/ run any resolver that isn't tagged "low-cost".
dataset = ChalkClient().offline_query(
input={User.id:[1,2,3]},
output=[
User.credit_score
],
recompute_features=True,
required_resolver_tags=["low-cost"]
)October 24, 2023
Support for Python 3.11
You can now use either of Python 3.11 or 3.10 on a per-environment basis.
project: my-project-id
environments:
default:
runtime: python310
develop:
runtime: python311See Python Version for more information.
October 23, 2023
Quality of Life Improvements
ChalkClient.query_bulk(...)andmulti_queryno longer require that references features
be defined as Python classes, and string names for inputs and outputs can now be used instead.
October 11, 2023
Alert descriptions
Alerts now support descriptions, which can be used to provide more context about the alert.
from chalk.monitoring import Chart, Series
Chart(name="Request count").with_trigger(
Series
.feature_null_ratio_metric()
.where(feature=User.fico_score) > 0.2,
description="""*Debugging*
When this alert is triggered, we're parsing null values from
a lot of our FICO reports. It's likely that Experian is
having an outage. Check the <dashboard|https://internal.dashboard.com>.
"""
)These descriptions can also be set in the Chalk dashboard via the metric alerts interface.
October 5, 2023
query_bulk support for notebooks
The query_bulk method is now available in the ChalkClient class. This method allows you to query for multiple rows of features at once.
This method uses Apache Arrow's Feather format to encode data. This allows the endpoint to transmit data (particularly numeric-heavy data) using roughly 1/10th the bandwidth that is required for the JSON format used by query.
This method has been available in beta for a few months, but is now available for general use, and as part of this release is now supported when querying using notebooks without access to feature schemas.
September 26, 2023
Improve scheduled resolver runs list
The list of scheduled resolvers now shows which resolvers are actually scheduled to run in the current environment, based on the environment argument to @online and @offline.
Resolvers that are annotated with an environment other than the current environment are labeled with the environment in which they are configured to run.
August 23, 2023
Improved chalk query output
The chalk query command now has improved output for errors. Previously, errors were displayed in a table, which meant that stacktraces were truncated:
> chalk query --in email.normalized=nice@chalk.ai --out email
Errors
Code Feature Resolver Message
─────────────────────────────────────────────────────────────────────────────
RESOLVER_FAILED src.resolvers.get_fraud_tags KeyError: 'tags'Now, errors are displayed in a more readable format, and stacktraces are not truncated:
> chalk query --in email.normalized=nice@chalk.ai --out email
Errors
Resolver Failed src.resolvers.get_fraud_tags
KeyError: 'tags'
File "src/resolvers.py", line 30, in get_fraud_tags
return parsed["tags"]
KeyError('tags')August 19, 2023
Query plan trace viewer
The query plan viewer now includes a flame graph visualization of the query plan's execution, called the Trace View. Precise trace data is stored for every offline query by default and for online queries when the query is made with the --explain flag.
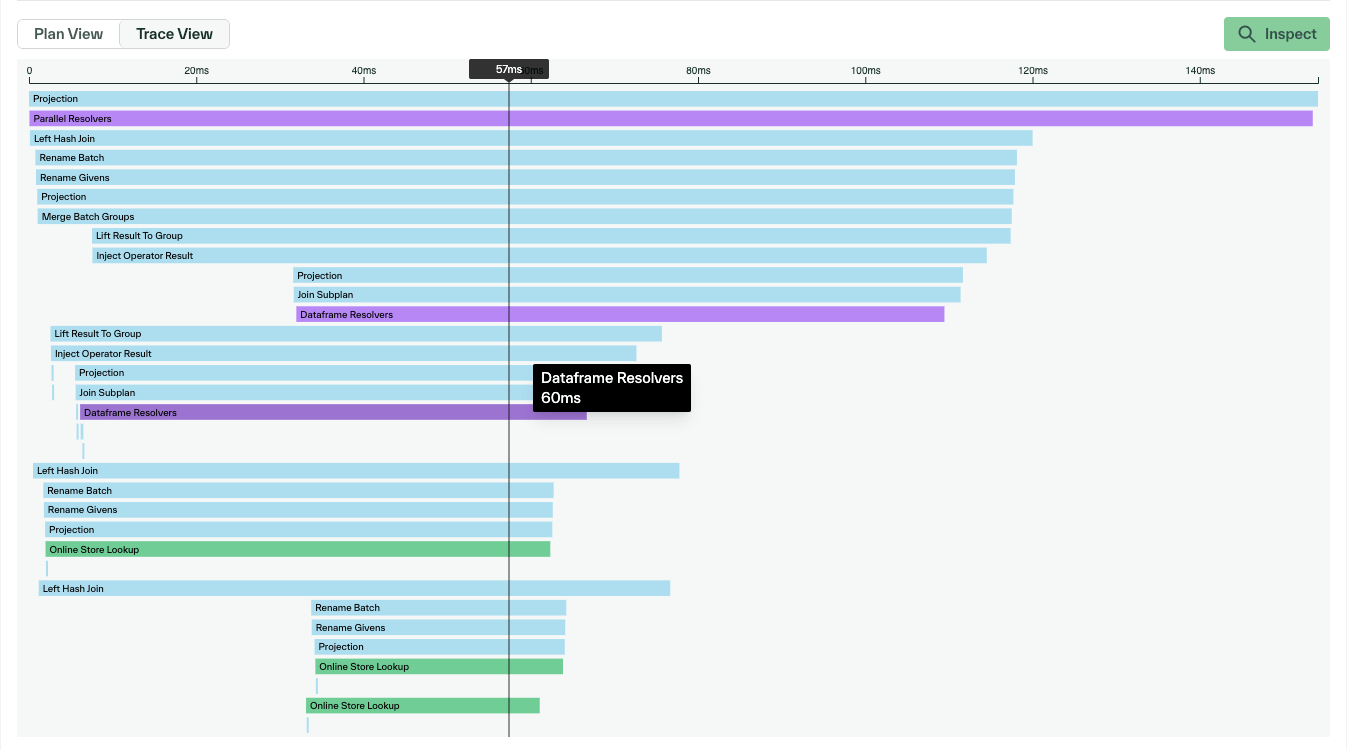
August 11, 2023
Override now in online query
- Support
now=for.query,--now, etc.
Query plan viewer improvements
- Redesigned query plan viewer
- Support viewing execution time per operator
- Support viewing data processing metrics per operator
- Query plans saved for all queries by default
No-input online and offline query improvements
offline_querynow supports running downstream resolvers when no input is provided. Query primary keys will be sampled or computed, depending on the value ofrecompute_features.online_querynow support running a query without any input. Query primary keys will be computed using an appropriate no-argument resolver that returns aDataFrame[...]
Misc
--localforchalk query, combineschalk apply --branchandchalk query --branch- The progress indicator in the
chalkcommand line tool is no longer an off-brand magenta.
August 5, 2023
Chalk Python SDK Improvements
Added: .to_polars(), to_pandas(), and .to_pyarrow() accept prefixed: bool as an argument. prefixed=True is the default behavior, and will prefix all column names with the feature namespace. prefixed=False will not prefix column names.
DataFrame({User.name: ["Andy"]}).to_polars(prefixed=False)
# output:
# polars DataFrame with `name` as the sole column.
DataFrame({User.name: ["Andy"]}).to_polars(prefixed=True)
# output:
# polars DataFrame with `user.name` as the sole column.Added: include_meta on ChalkClient.query(...), which includes .meta on the response object. This metadata object includes useful information about the query execution, at the cost of increased network payload size and a small increase in latency.
July 25, 2023
Freezing time in unit tests
Chalk now supports freezing time in unit tests. This is useful for testing time-dependent resolvers.
from datetime import timezone, datetime
from chalk.features import DataFrame, after
from chalk.features.filter import freeze_time
df = DataFrame([...])
with freeze_time(at=datetime(2020, 2, 3, tzinfo=timezone.utc)):
df[after(days_ago=1)] # Get items after february 2ndfreeze_time also works with resolvers that declare specific time bounds for their aggregation inputs:
@online
def get_num_transactions(txs: Card.transactions[before(days_ago=1)]) -> Card.num_txs:
return len(txs)
with freeze_time(at=datetime(2020, 9, 14)):
num_txs = get_num_transactions(txs) # num transactions before september 13thJuly 11, 2023
Explicitly time-dependent resolvers
Chalk now supports resolvers that are explicitly time-dependent. This is useful for performing backfills which compute values that depend on values that are semantically similar to datetime.now().
You can express time-dependency by declaring a dependency on a special feature called Now:
@online
def get_age_in_years(birthday: User.birthday, now: Now) -> User.age_in_years:
return (now - birthday).yearsIn online query, (i.e. with ChalkClient().query), Now is datetime.now(). In offline query contexts, now will be set to the appropriate input_time value for the calculation. This allows you to backfill a feature for a single entity at many different historical time points:
ChalkClient().offline_query(input={User.id: [1,1,1]}, output=[User.age_in_years], input_times=[
datetime.now() - timedelta(days_ago=100),
datetime.now() - timedelta(days_ago=50),
datetime.now() - timedelta(days_ago=0),
])
...Now can be used in batch resolvers as well:
@online
def batch_get_age_in_years(df: DataFrame[User.id, User.birthday, Now]) -> DataFrame[User.id, User.age_in_years]:
...June 21, 2023
Testing your SQL File Resolvers
SQL file resolvers are Chalk's preferred method of resolving features with SQL queries. Now, you can get your SQL file resolvers in Python by the name of the SQL file resolver. For example, if you have the following SQL file resolver:
-- source: postgres
-- cron: 1h
-- resolves: Person
select id, name, email, building_id from table where id=${person.id}you can test out your resolver with the following code.
from chalk import get_resolver
resolver = get_resolver('person') # get_resolver('person.chalk.sql') will also work
result = resolver('my_id')June 15, 2023
Metrics Export Updates
Now, Chalk supports exporting metrics about "named query" execution. These metrics (count, latency) join similar metrics about feature and resolver execution. Contact your Chalk Support representative to configure metrics export if you would like to view metrics about Chalk system execution in your existing metrics dashboards.
Additional updates:
- synthetic cache resolvers are now excluded
- query_name is a tag on many metrics
June 14, 2023
Branch deployment performance
Chalk Branch Deployments provide an excellent experience for quick iteration cycles on new features and resolvers. Now, Chalk Branch Deployments automatically use a pool of "standby" workers, so there is less delay before queries can be served against a new deployment. This reduces the time it takes to run query or offline query against a new deployment from ~10-15 seconds to ~1-3 seconds. This impacts customers with more complex feature graphs the most.
June 13, 2023
Expanded support for logical keying in streaming contexts
Stream resolvers support a keys= parameter. This parameter allows you to re-key a stream by a property of the message, rather than relaying on the protocol layer key. This is appropriate if a stream is keyed randomly, or by an entity key like "user", but you want to aggregate along a different axis, e.g. "organization".
Now, keys= supports passing a "dotted string" (e.g. foo.bar) to indicate that Chalk should use a sub-field of your message model. Previously, only root-level fields of the model were supported.
DataFrame unit tests
If you specify projections or filters in DataFrame arguments of resolvers, Chalk will automatically project out columns and filter rows in the input data.
Below, we test a resolver that filters rooms in a house to only the bedrooms:
@features
class Room:
id: str
home_id: "Home.id"
name: str
@features
class Home:
id: str
rooms: DataFrame[Room]
num_bedrooms: int
@online
def get_num_bedrooms(
rooms: Home.rooms[Room.name == 'bedroom']
) -> Home.num_bedrooms:
return len(rooms)Now, we may want to write a unit test for this resolver.
def test_get_num_rooms():
# Rooms is automatically converted to a `DataFrame`
rooms = [
Room(id=1, name="bedroom"),
Room(id=2, name="kitchen"),
Room(id=3, name="bedroom"),
]
# The kitchen room is filtered out
assert get_num_bedrooms(rooms) == 2
# `get_num_bedrooms` also works with a `DataFrame`
assert get_num_bedrooms(DataFrame(rooms)) == 2While we could have written this test before, we would have had to manually filter the input data to only include bedrooms. Also note that Chalk will automatically convert our argument to a DataFrame if it is not already one.
June 12, 2023
Query Run Page
Chalk's dashboard shows aggregated logs and metrics about the execution of queries and resolvers. Now, it can also show detailed metrics for a single query. This is useful for debugging and performance tuning.
You can access this page from the "runs" tab on an individual named query page, or from the "all query runs" link on the "queries" page.
You can search the list of previously executed queries by date range, or by "query id". The query id is returned in the "online query" API response object.
May 15, 2023
BigTable Online Storage
Chalk now supports BigTable as an online-storage implementation. BigTable is appropriate for customers with large working sets of online features, as is common with recommendation systems. We have successfully configured BigTable to serve 700,000 feature vectors per second at ~30ms p90 e2e latency.
May 10, 2023
Enhancements to Offline Query
The Offline Query has been enhanced with a new recompute_features parameter. Users can control which features are sampled from the offline store, and which features are recomputed.
- The default value
Falsewill maintain current behavior, returning only samples from the offline store. Truewill ignore the offline store, and execute@onlineand@offlineresolvers to produce the requested output.- If, instead, the user passes in a list of features to
recompute_features, those features will be recomputed by running@onlineand@offlineresolvers, and all other feature values - including those needed to recompute the requested features - will be sampled from the offline store.
Recompute Dataset
The 'recompute' capability is also exposed on Dataset. When passed a list of features to recompute, a new Dataset Revision will be generated, and the existing dataset will be used as inputs to recompute the requested features.
Developing in Jupyter
Chalk has introduced a new workflow when working with branches, allowing full iterations to take place directly in any IPython notebook. When a user creates a Chalk Client with a branch in a notebook, subsequent features and resolvers in the notebook will be deployed to that branch. When combined with Recompute Dataset and the enhancements to Offline Query, users have a new development loop available for feature exploration and development:
- Take advantage af existing data in chalk
- Explore that data using familiar tools in a notebook
- Enrich the data by developing new features and resolvers
- Immediately view the results of adjusting features in the dataset
- When exploration is complete, features and resolvers can be directly added back to the Chalk project
May 5, 2023
View Deployment Source Code
Deployments now offer the ability to view their source code. By clicking the "View Source" button on the Deployment Detail page, users can view all files included in the deployed code.
April 21, 2023
Improved Deployment Utilities
Users can now "redeploy" any historical deployment with a UI button on the deployment details page. This enables useful workflows including rollbacks. The "download source" button downloads a tarball containing the deployed source to your local machine.
April 18, 2023
Resolver error messages for incorrect types include primary keys
When writing resolvers, incorrect typing can be a difficult to track. Now, if a resolver instantiates a feature of an incorrect type, the resolver error message will include the primary key value(s) of the query itself.
April 11, 2023
Online query improvements
The Online Query API can now be used to query DataFrame-typed features. For instance, you can query all of a user's transaction level features in a single query:
chalk query --in user.id --out user.transactions
{
"columns": ["transaction.id", "transaction.user_id", ...],
"values": [[1, 2, 3, ...], ["user_1", "user_2", "user_3", ...]
}More functionality will be added to Online and Offline query APIs to support more advanced query patterns.
April 6, 2023
Branch deployments
When deploying with chalk apply a new flag --branch <branch_name> has been introduced which creates a branch deployment. Users can interact with their branch deployment using a consistent name by passing the branch name to query, upload_features, etc. Chalk clients can also be scoped to a branch by passing the branch in the constructor. Branch deployments are many times faster than other flavors of chalk apply, frequently taking only a few seconds from beginning to end. Branch deployments replace preview deploys, which have been deprecated.
March 31, 2023
Speed improvements for deployments
Deployments via chalk apply are now up to 50% faster in certain cases. If your project's PIP dependencies haven't changed, new deployments will build & become active significantly faster than before.
March 17, 2023
Offline TTL
Introduces a new "offline_ttl" property to features decorator . Now you can control for how long data is valid in the offline_store. Any feature older than the ttl value will not be returned in an offline query.
@features
class MaxOfflineTTLFeatures:
id: int
ts: datetime = feature_time()
no_offline_ttl_feature: int = feature(offline_ttl=timedelta(0))
one_day_offline_ttl_feature: int = feature(offline_ttl=timedelta(days=1))
infinite_ttl_feature: intStrict Feature Validation
Adds the strict property to features decorator, indicating that any failed validation will throw an error. Invalid features will never be written to the online or offline store is strict is True. Also introduces the validations array to allow differentiated strict and soft validations on the same feature.
@features
class ClassWithValidations:
id: int
name: int = feature(max=100, min=0, strict=True)
feature_with_two_validations: int = feature(
validations=[
Validation(min=70, max=100),
Validation(min=0, max=100, strict=True),
]
)March 7, 2023
Datasets in Offline Query
The Dataset class is now live! Using the new ChalkClient.offline_query method, we can inspect important metadata about the query and retrieve its output data in a variety of ways.
Simply attach a dataset_name to the query to persist the results.
from chalk.client import ChalkClient, Dataset
uids = [1, 2, 3, 4]
at = datetime.now()
dataset: Dataset = ChalkClient().offline_query(
input={
User.id: uids,
},
input_times=[at] * len(uids),
output=[
User.id,
User.fullname,
User.email,
User.name_email_match_score,
],
dataset_name='my_dataset'
)
pandas_df: pd.DataFrame = dataset.data_as_pandasCheck out the documentation here.
February 28, 2023
Deployment Build Logs
Chalk now provides access to build and boot logs through the Deployments page in the dashboard.
February 16, 2023
Resolver timeouts
Computing features associated with third-party services can be unpredictably slow. Chalk helps you manage such uncertainty by specifying a resolver timeout duration.
Now you can set timeouts for resolvers!
@online(timeout="200ms")
def resolve_australian_credit_score(driver_id: User.driver_id_aus) -> User.credit_score_aus:
return experian_client.get_score(driver_id)January 26, 2023
SQL File Resolvers
SQL-integrated resolvers can be completely written in SQL files: no Python required! If you have a SQL source like as follows:
pg = PostgreSQLSource(name='PG')You can define a resolver in a .chalk.sql file, with comments that detail important metadata. Chalk will process it upon chalk apply as it would any other Python resolver.
-- type: online
-- resolves: user
-- source: PG
-- count: 1
select email, full_name from user_table where id=${user.id}Check out the documentation here.
January 12, 2023
Improved Logging
Logging on your dashboard has been improved. You can now scroll through more logs, and the formatting is cleaner and easier to use. This view is available for resolvers and resolver runs.

January 9, 2023
Pretty Print Online Query Results
Online Query Response objects now support pretty-print in any iPython environment.

January 8, 2023
Linux docker containers on M1 Macs
chalkpy has always supported running in docker images using M1's native arm64 architecture, and now chalkpy==1.12.0 supports most functionality on M1 Macs when run with AMD64 (64 bit Linux) architecture docker images. This is helpful when testing images built for Linux servers that include chalkpy.
January 6, 2023
Docs Search
Chalk has lots of documentation, and finding content is now difficult.
We've added docs search!

Try it out by typing cmd-K, or clicking the search button at the top of the table of contents.
September 27, 2022
Tags & Owners as Comments
This update makes several improvements to feature discovery.
Tags and owners are now parsed from the comments preceding the feature definition.
@features
class RocketShip:
# :tags: **team:identity**, **priority:high**
# :owner: **katherine.johnson@nasa.gov**
velocity: float
...Prior to this update, owners and tags needed to be set in the feature(...) function:
@features
class RocketShip:
velocity: float = feature(
tags=["**team:identity**", "**priority:high**"],
owner="**katherine.johnson@nasa.gov**"
)
...Feel free to choose either mechanism!
July 28, 2022
Auto Id Features
It's natural to name the primary feature of a feature class id. So why do you always have to specify it? Until now, you needed to write:
@features
class User:
id: str = feature(primary=True)
...Now you don't have to! If you have a feature class that does not have a feature with the primary field set, but has a feature called id, it will be assigned primary automatically:
@features
class User:
id: str
...The functionality from before sticks around: if you use a field as a primary key with a name other than id, you can keep using it as your primary feature:
@features
class User:
user_id: str = feature(primary=True)
# Not really the primary key!
id: strJuly 25, 2022
DataFrame Expressions
The Chalk DataFrame now supports boolean expressions! The Chalk team has worked hard to let you express your DataFrame transformations in natural, idiomatic Python:
DataFrame[
User.first_name == "Eleanor" or (
User.email == "eleanor@whitehouse.gov" and
User.email_status not in {"deactivated", "unverified"}
) and User.birthdate is not None
]Python experts will note that or, and, is, is not, not in, and not aren't overload-able. So how did we do this? The answer is AST parsing! A more detailed blog post to follow.
July 22, 2022
Descriptions as Comments
This update makes several improvements to feature discovery.
Descriptions are now parsed from the comments preceding the feature definition. For example, we can document the feature User.fraud_score with a comment above the attribute definition:
@features
class User:
# **0 to 100 score indicating an identity match.**
# **Low scores indicate safer users**
fraud_score: float
...Prior to this update, descriptions needed to be set in the feature(...) function:
@features
class User:
fraud_score: float = feature(description="""
**0 to 100 score indicating an identity match.**
**Low scores indicate safer users**
""")
...The description passed to feature(...) takes precedence over the implicit comment description.
Namespace Metadata
You can now set attributes for all features in a namespace!
Here, we assign the tag group:risk and the owner ravi@chalk.ai to all features on the feature class. Owners specified at the feature level take precedence (so the owner of User.email is the default ravi@chalk.ai whereas the owner of User.flaky_api_result is devops@chalk.ai). Tags aggregate, so email has the tags pii and group:risk.
@features(tags="group:risk", owner="ravi@chalk.ai")
class User:
email: str = feature(tags="pii")
flaky_api_result: str = feature(owner="devops@chalk.ai")July 14, 2022
Self-Serve Slack Integration
You can configure Chalk to post message to your Slack workspace! You can find the Slack integration tab in the settings page of your dashboard.
Slack can be used as an alert channel or for build notifications.
July 13, 2022
Python 3.8 Support
Chalk's pip package now supports Python 3.8! With this change, you can use the Chalk package to run online and offline queries in a Python environment with version >= 3.8. Note that your features will still be computed on a runtime with Python version 3.10.
July 8, 2022
Named Integrations
Chalk's injects environment variables to support data integrations. But what happens when you have two data sources of the same kind? Historically, our recommendation was to create one set of environment variables through an official data source integration, and one set of prefixed environment variables yourself using the generic environment variable support.
With the release of named integrations, you can connect to as many of the same data source as you need! Provide a name at the time of configuring your data source, and reference it in the code directly. Named integrations inject environment variables with the standard names prefixed by the integration name (ie. RISK_PGPORT). The first integration of a given kind will also create the un-prefixed environment variable (ie. both PGPORT and RISK_PGPORT).
June 29, 2022
SOC 2 Report
Chalk is excited to announce the availability of our SOC 2 Type 1 report from Prescient Assurance. Chalk has instituted rigorous controls to ensure the security of customer data and earn the trust of our customers, but we're always looking for more ways to improve our security posture, and to communicate these steps to our customers. This report is one step along our ongoing path of trust and security.
If you're interested in reviewing this report, please contact support@chalk.ai to request a copy.
June 3, 2022
Pandas Integration
You can now convert Chalk's DataFrame to a pandas.DataFrame and back! Use the methods chalk_df.to_pandas() and .from_pandas(pandas_df).
Migration Sampling
The 1.4.1 release of the CLI added a parameter --sample to chalk migrate. This flag allows migrations to be run targeting specific sample sets.
Feature/Resolver Health
Added spark lines to the feature and resolver tables which show a quick summary of request counts over the past 24 hours. Added status to feature and resolver tables which show any failing checks related to a feature or resolver.