Model Platform
LLM Toolchain
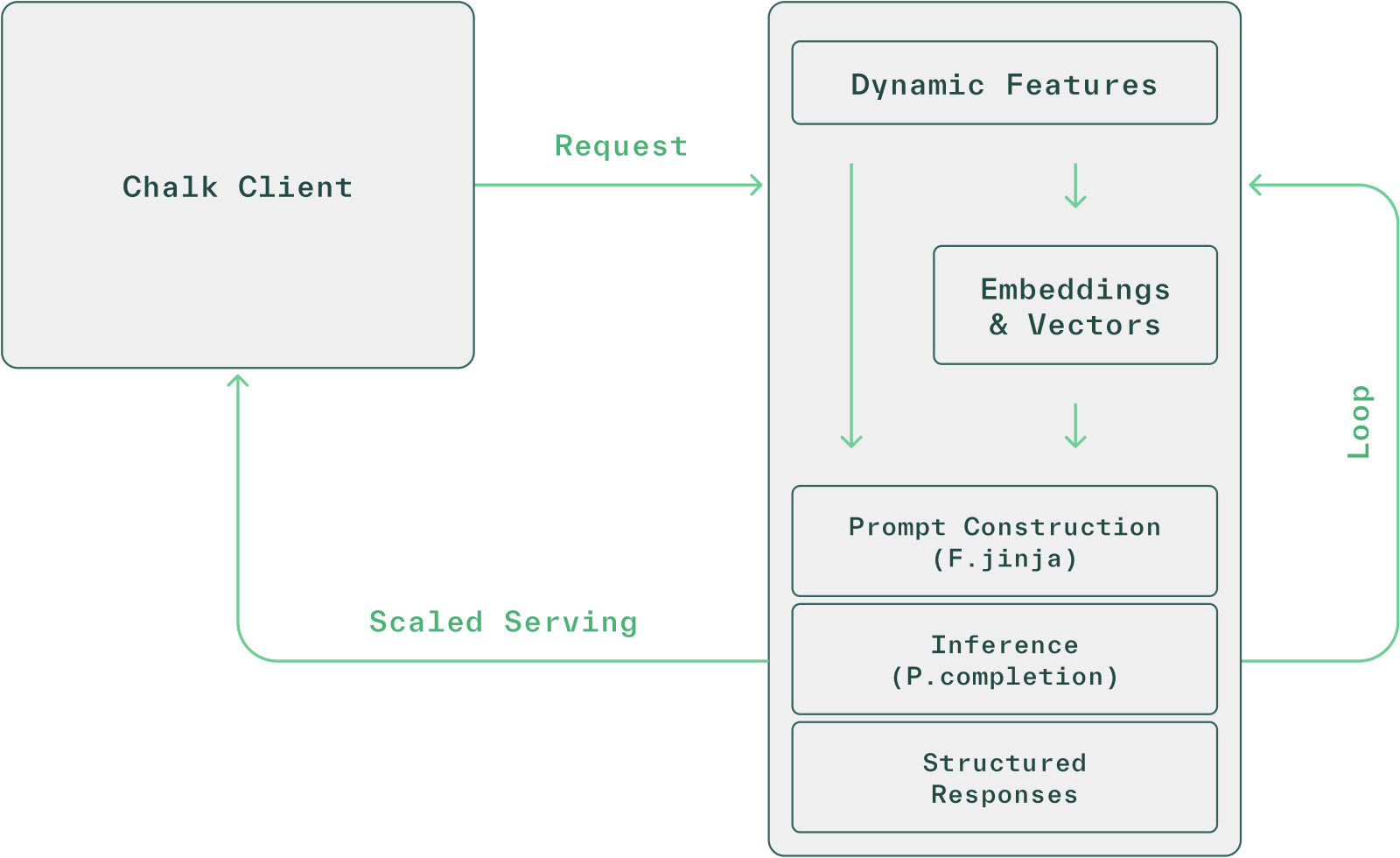
Easily integrate unstructured data, build context-aware prompts, and run LLM evaluations at scale with Chalk.
Chalk’s LLM toolchain enables you to build enterprise-grade AI applications without stitching together LLMs, prompts, vector DBs, and retrieval logic:
- Call chat completion APIs out-of-the-box
- Cache expensive computations to avoid redundant processing and reduce latency
- Retrieve real-time context into LLMs
- Generate embeddings and vectors within pipelines
- Reuse and manage prompts with named prompts
- Run large-scale evaluations using historical traffic to compare prompt variants
Chalk provides a full-stack solution but can also integrate seamlessly with your current infrastructure. For instance, you can use an existing vector DB to store and retrieve your embeddings, while leveraging Chalk to evaluate new models and prompts. Chalk lets you integrate only the pieces you need:
import chalk.functions as F
import chalk.prompts as P
from chalk.features import DataFrame, Primary, Vector, embed, features, has_many, _
from pydantic import BaseModel
# Use structured output to easily incorporate unstructured data in our ML pipelines
class AnalyzedReceiptStruct(BaseModel):
expense_category: ExpenseCategoryEnum
business_expense: bool
loyalty_program: str
return_policy: int
@features
class Transaction:
id: int
merchant_id: Merchant.id
merchant: Merchant
receipt: Receipt
llm: P.PromptResponse = P.completion(
model="gpt-5.1-2025-11-13",
messages=[P.message(
role="user",
content=F.jinja(
"""Analyze the following receipt:
Line items: {{Transaction.receipt.line_items}}
Merchant: {{Transaction.merchant.name}} {{Transaction.merchant.description}}""")
)],
output_structure=AnalyzedReceiptStruct,
)
# cache forever since transaction is finalized
expense_category: str = features(
max_staleness="infinity",
expression=F.json_value(
_.llm.response, # from LLM
"$.expense_category",
),
)
# or configure the chat completion from your Chalk dashboard
llm_call_with_named_prompt: P.run_prompt("analyze_receipt-v1")
@features
class ProductRec:
user_id: Primary[User.id]
user: User
# generate embeddings
user_vector: Vector = embed(
input=F.array_join(F.array_agg(
_.user.products[
_.name,
_.type == "liked"
]),
delimiter=" || ",
),
provider="vertexai",
model="text-embedding-005",
)
# do a vector search with the generated embedding
similar_users: DataFrame[User] = has_many(
lambda: ProductRec.user_vector.is_near(
User.liked_products_vector
)
)Chalk eliminates the complexity of orchestrating data and ETL pipelines by building a dependency graph (DAG) of your features, which are defined using Python. At inference time, Chalk dynamically builds query plans (subgraphs of your feature DAG) without manual configuration, based on the features you request. The (structured) outputs of chat completions are treated as just newly computed features and can feed into other feature computations until all of the features requested are computed.
Call chat completion APIs out-of-the-box with Chalk's Completion function
Use Chalk’s P.completion function to call LLMs from within your feature classes.
Easily create structured LLM responses with full control over model selection, prompt construction, and output formatting.
Combined with F.jinja templates, you can dynamically inject relevant feature values into your prompts for context-aware responses.
@features
class Transaction:
llm: P.PromptResponse = P.completion(
model="gpt-5.1-2025-11-13",
messages=[...],
)P.completion accepts a range of parameters for fine-tuning your LLM interactions, including:
- Model selection
- Temperature control for output randomness
- Token limits
- Structured output formatting via Pydantic models
- Various provider-specific settings
You can also set timeout values, retry logic, and custom stop sequences to build the exact experience your application requires. Visit our API documentation for a complete reference of all available parameters.
After executing a completion, Chalk returns a P.PromptResponse object that encapsulates the complete interaction, including:
response: the model’s generated textprompt: the original prompt for contextusage: token usage and cost metricsruntime_stats: execution timing data to help you monitor and optimize your model interactions
class PromptResponse(BaseModel):
response: Optional[str] = Field(
description="Response from the model. Raw string if no output structure specified, json encoded string otherwise. `None` if the response was not received or incorrectly formatted."
)
prompt: Prompt
usage: Usage
runtime_stats: RuntimeStatsAfter receiving a response from an LLM via Chalk’s completion function, you can easily extract specific fields from the structured response using F.json_value.
The extracted LLM-generated values become referenceable like ordinary features:
@features
class Transaction:
id: int
llm: P.PromptResponse
expense_category: str = F.json_value(
_.llm.response, # from LLM
"$.expense_category",
)You can also compose multimodal prompts — combining image and text in a single call using P.completion(...).
This unlocks image analysis workflows like receipt or PDF parsing with minimal code.
@features
class Receipt:
image_url: str
image_response: P.MultimodalPromptResponse = P.completion(
model="gpt-5.1",
messages=[
P.message(
"user",
[
{"type": "input_text", "text": "describe this image"},
{"type": "input_image", "image_url": _.image_url},
],
),
],
)Chalk’s LLM toolchain streamlines the entire experience of working with language models by providing:
- Direct access to LLM providers without managing API keys, request formatting, or response parsing
- A consistent API interface regardless of which LLM provider you’re using
- Automatic tracking of token usage, costs, and performance metrics
- Built-in error handling with automatic retries without additional code
- Easy extraction of fields from LLM responses for direct use as features
- Seamless integration with Chalk’s feature system for dynamic data incorporation through
F.jinja
Cache expensive computations to avoid redundant processing and reduce latency with Chalk's max_staleness setting
Chalk makes it easy to cache features.
This is done by setting the max_staleness of a feature, which lets you specify how old a cached feature value can be before it must be recomputed.
This gives you full control in balancing freshness and performance requirements.
You can specify cache duration in multiple ways:
| Value | Description |
|---|---|
"30d" "1h" "15m" | Natural language strings |
timedelta(hours=1) | Python timedelta objects |
"infinity" | Permanent caching for immutable data |
These settings can be overridden at query time for additional flexibility.
@features
class User:
id: int
# from API or 3rd-party client
credit_score: int = features(
max_staleness="30d",
)
@features
class Transaction:
id: int
llm: P.PromptResponse
# cache forever since transaction is finalized
expense_category: str = features(
max_staleness="infinity",
expression=F.json_value(
_.llm.response, # from LLM
"$.expense_category",
),
)Retrieve real-time context to give LLMs with Chalk's Jinja function
Chalk’s F.jinja function lets you build prompts with live data.
Feature values are accessed with the jinja double curly brace sytanx: {{ feature_name }}.
F.jinja(
"""Analyze the following receipt:
Line items: {{Transaction.receipt.line_items}}
Merchant: {{Transaction.merchant.name}} {{Transaction.merchant.description}}"""
)Benefits of using Jinja for LLM prompting:
- Improve performance by dynamically incorporating real-time data from Chalk features
- Reduce token usage by only including relevant context in your prompts
- Iterate on prompts faster with a structured template system that allows quick experimentation while maintaining consistency across team workflows
Generate embeddings and vectors within pipelines with Chalk's embed function
Convert structured or unstructured data into embeddings with one line.
Chalk’s embedding function automatically converts your features into vector embeddings for similarity search, etc. with built-in support for popular embedding models.
Running in your VPC gives you quick and secure access to models like Bedrock and Gemini with minimal overhead and configuration, as Chalk abstracts away connecting to model providers.
@features
class ProductRec:
user_id: Primary[User.id]
user: User
bio_embeddings: Vector = embed(
input=lambda: ProductRec.user.bio,
provider="vertexai",
model="text-embedding-005",
)When using Chalk’s built-in embedding functions, the vector dimensions don’t need to be specified, as Chalk will automatically infer it from the embedding model.
Reuse and manage prompts with Chalk's named prompts
You can define named prompts directly from your Chalk dashboard to help maintain consistency in your LLM workflows. This centralized approach makes prompts more maintainable and reusable across your application, while also allowing you to change your prompts and model providers without needing to redeploy Chalk.
@features
class Transaction:
id: int
merchant_id: Merchant.id
merchant: Merchant
receipt: Receipt
# or configure the chat completion from your Chalk dashboard
llm_call_with_named_prompt: P.PromptResponse = P.run_prompt("analyze_receipt-v1")The P.run_prompt() function provides a clean syntax for connecting your feature classes to a named prompt.
You can edit prompt templates directly from your Chalk dashboard and test features with different prompts without changing any code, making iteration and refinement much faster.
Run large-scale evaluations using historical traffic with Chalk's feature store for realistic offline testing
Chalk prompt evaluations provide systematic comparison of prompt variants against historical datasets, supporting customizable metrics, reference outputs, and distributed processing for large-scale prompt experimentation. Built-in evaluators like “exact_match” measure accuracy against reference outputs, while custom evaluation expressions allow for domain-specific metrics tailored to your application needs.
eval_run = chalk_client.prompt_evaluation(
dataset_name="sentiment_gt",
evaluators=["exact_match"],
reference_output="user.actual_sentiment",
prompts=[
"analyze_sentiment-v1",
"analyze_sentiment-v2",
P.completion(
model="gpt-5.1",
messages=[
P.message(role="system", content=system_message),
P.message(role="user", content=user_message),
],
),
]
)
eval_run.to_pandas()Benefits of leveraging a feature store for evaluation:
- Test against historical traffic and usage patterns from your production environment
- Identify edge cases and failure modes before they affect real users
- Run thousands of evaluations in parallel without impacting live systems
View your eval results from the Chalk dashboard to track important metrics such as accuracy, average tokens, P50 latency, and P99 latency.