- Feature Engine
- Frequently Asked Questions
Feature Engine
Frequently Asked Questions
A collection of questions frequently asked by customers
Getting support
The questions are sorted by category. Don’t see your question answered? Please reach out via your support channel and we will be happy to help!
Data Sources and Infrastructure
What is the difference between the online store and the offline store?
The online store is intended to store features for low-latency retrieval in online query. Typically, the online store is implemented using Redis or DynamoDB.
The offline store is intended to store historical logs of all previously ingested or computed features. It is used to compute large historical training sets. It is typically implemented using BigQuery, Snowflake, Iceberg, or other data warehouses.
Can we do RBAC (Role Based Access Control) within Chalk?
Yes! Within the dashboard you can assign roles with different permissions to different users. The default roles available are shown below.
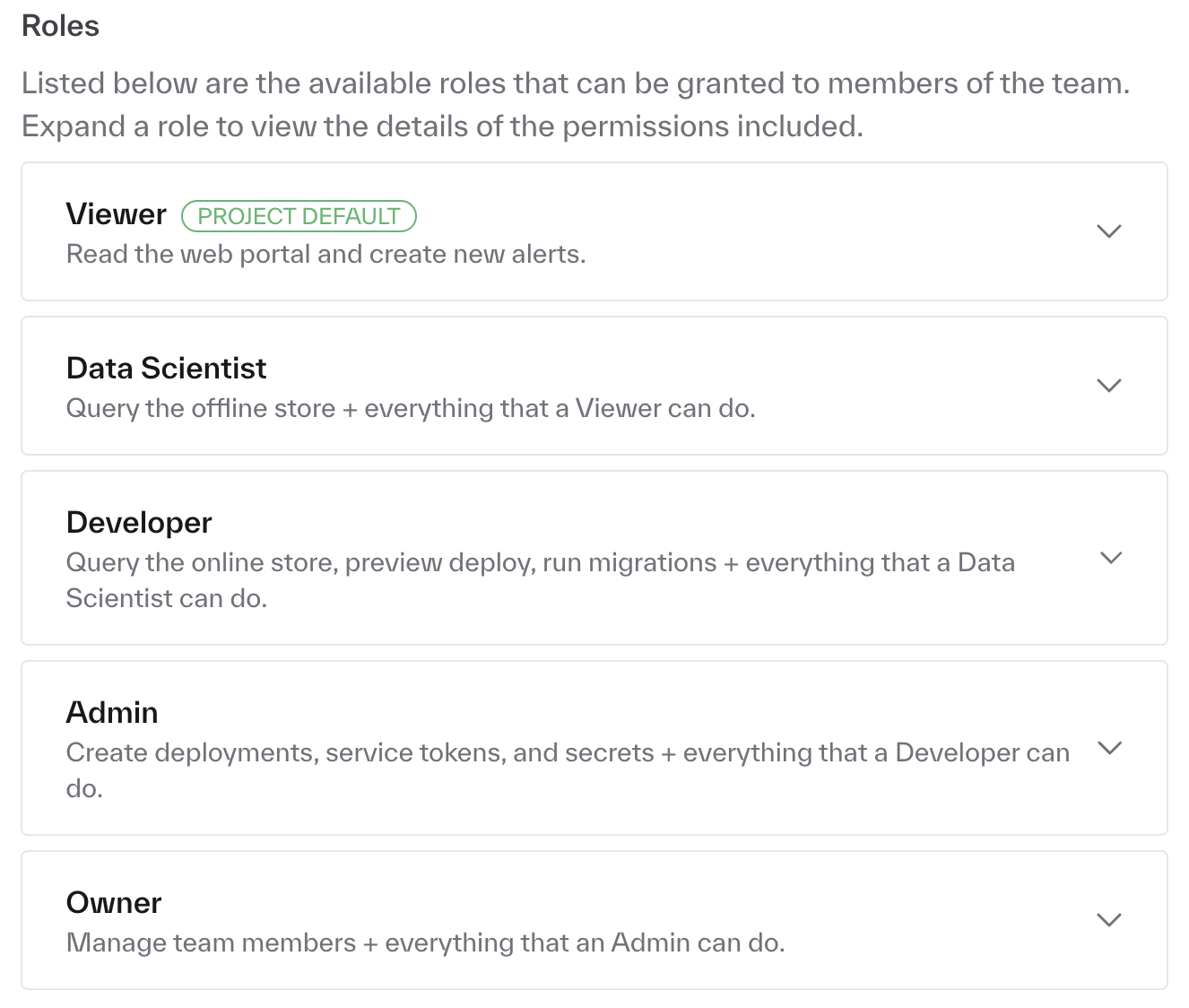
What are the necessary steps for us to get Chalk in our system?
Please reach out via your support channel and we’d be happy to walk you through how to get Chalk setup running on your cloud infrastructure!
We use Okta SCIM provisioning. Can we import these roles to be used in Chalk?
Yes! You can set up Okta to automatically provision and deprovision Chalk users. For more information on how, see here.
How should I set up secrets to be accessible in our deployed environments?
You can configure secrets as environment variables in the Secrets tab of Settings in your Chalk dashboard, and
these secrets would then be available on the next deploy in the environments that you’ve specified, and on all
branches in those environments!
Features
Does Chalk have a feature catalog?
Yes! You can view all the features for all namespaces deployed in your environments, along with some metadata on recent activity and updates.
How should I use feature versioning?
You can define versions for features if, for example, you are iterating on feature definitions. We’d recommend setting a default feature version for ensuring consistency across feature references. For more information, please see this tutorial on feature versions
How does FeatureTime work? Should I override FeatureTime with timestamps from existing data sources?
Feature time is the time at which a feature was observed. By default, feature time is set to the feature’s resolver execution time. You can override feature time and may want to do so if you’re ingesting historical data. For more information on how feature times work, see our time documentation.
How should I structure my windowed features? What kind of windows can I use?
We recommend writing windowed features for aggregated computations over different time periods. You can define the different windows in terms of weeks, days, hours, minutes, or even seconds (weeks=“w”, days=“d”, hours=“h”, minutes=“m”, seconds=“s”). Under the hood, we normalize the time representations into durations in seconds, so you would have multiple syntactical options for accessing different windows for features. We recommend setting default values for windowed features in case there are windows with no events during the specified time period. Otherwise, you can write resolvers defining how your windowed features should be computed and pass windowed features as inputs into resolvers just like normal features!
Can I upload features into the online store with an API endpoint?
Yes! In addition to streaming and scheduled bulk ingests of features, you can submit requests using
the upload_features SDK endpoints to synchronously ingest features into the online or offline stores
using API clients.
Resolvers
What is the difference between an online and offline resolver?
Not much! The only difference is in which contexts the resolvers are executed. A few key scenarios:
- in “online query” (i.e. queries submitted via
.query,.query_bulk,multi_query), offline resolvers never execute. - in “offline query” (i.e. queries submitted via
.offline_query), offline resolvers are preferred, taking precedence over online resolvers that compute the same features. - in offline query,
onlineresolvers are permitted to execute
@offline is intended to be used for resolvers whose backing data sources are too slow or expensive
to fulfill online query requests — i.e. data warehouses or certain API sources, but
if your query requests can tolerate the latency of one of these slow sources, you can mark resolvers
using those datasources @online to query them on-the-fly.
On the other hand, if your query requests can’t tolerate the latency of the underlying data store,
evaluate using scheduled ingestion or streaming resolvers in order to ensure that fresh
data is available in the online store.
How do I force certain resolvers to execute in my query?
Make use of tags=[...]. If a resolver is marked with a tag, it is only eligible to execute in
queries that have a matching tag. An even stricter variant of this concept is available with the
required_resolver_tags argument to query and offline_query which allows you to force all
resolvers to have a particular tag.
How do I know when my resolver will run and when it will time out?
You can set cron schedules for your resolvers, which will be parsed in your local system’s timezone. You can also set customized timeouts for resolvers. Chalk currently has a max timeout of 18 hours for resolvers, but if this does not suit your needs, please reach out to us in your support channel with a description of your compute needs for your resolver!
How do I know if my resolver is still running?
The best way to check if your resolver is still running is to see if there are still resources provisioned to run
your resolver. For scheduled resolver runs, you can view an overview of Run History as well as a view of Cloud
Resources dedicated to scheduled resolver runs under the Runs tab on the menu sidebar. For triggered resolver
runs, you can also find which pod is running your resolver on the run page. Finally, if you navigate to
Infrastructure > Resource Configuration, you can view all pods currently running in your cluster, whether for resolver runs or
queries.
How should I work with dataframes in my resolvers?
You can define resolvers with DataFrame inputs or outputs, which uses the
Chalk DataFrame structure. You can do some aggregations and projections
using the Chalk DataFrame, but you can also convert the Chalk DataFrames into Pandas or Polars using .to_pandas()
and .to_polars() for more data manipulation.
Querying
Can I query for two different feature classes in a single query?
We recommend creating a “root” feature class that models the interaction between the two entities — i.e. if need “customer” and “business” features for a transaction fraud model, you might create a class like this:
@features
class AuthQuery:
# A unique ID that represents this interaction; may be randomly generated if you have
# no natural ID in your system.
id: str
# A reference to the relevant customer.
customer_id: "Customer.id"
customer: Customer
# A reference to the relevant business.
business_id: "Business.id"
business: BusinessThen, queries can be submitted using:
ChalkClient().query(
input={
AuthQuery.id: ...,
AuthQuery.customer_id: ...,
AuthQuery.business_id: ...,
},
output=[
AuthQuery.customer,
AuthQuery.business,
]
)How do I query for multiple entities at the same time?
Use the .query_bulk SDK method instead of .query. For example, to query features for multiple Hospital entities, you might use:
result = ChalkClient().query_bulk(
input={Hospital.id: [1,2,3,4,5]}
output=[Hospital.current_waiting_time, Hospital.has_trauma_bay, Hospital.has_er, Hospital.has_mri]
)
df = result[0].to_pandas()How do I tell if my offline query is still running if it shows as In Progress in the UI?
The first thing to check is whether there is a pod in your cluster running your offline query. You can verify this
by viewing the pods running under Infrastructure. If you’re running an offline query from a notebook, then
the polling may timeout even if the offline query is still running, so the best way to verify the status of your
offline query is a combination of checking the query run in dashboard and the status of pods in the cluster. For more
visibility, you can also add the run_asynchronously=True argument to ChalkClient.offline_query to explicitly run
your offline query on an isolated worker so you can use the worker status as a query status.
How do I sample instances of a feature class?
You can query for random instances of a feature class by running an offline query and specifying the max_samples
parameter. For instance, running the example query below will sample ten random users from the User feature class,
returning the features specified by the output parameters: [User.id, User.name, User.age].
from chalk.client import ChalkClient
from datetime import datetime
from src.feature_sets import User
client = ChalkClient()
dataset = client.offline_query(
output=[User.id, User.name, User.age],
max_samples=10,
recompute_features=True
)
df = dataset.get_data_as_pandas()Deployment
How are resources provisioned for my Chalk cluster, and can I modify the configuration?
We have default resource configurations for general environments.
You can modify the configuration for your project’s cloud resources by modifying the specs under
Infrastructure > Resource Configuration. You must hit Save and Apply Changes in order for
your configuration changes to go through. If you are not sure how you should configure your cloud resources,
please reach out to us in your support channel!
Can I suspend or delete branches when they are not in use?
You cannot currently suspend or delete branches, but stale branches do not consume resources, so there is no cost or performance impact from old branches.
Observability and Testing
Is my (resolver / query) running?
See answers above under Resolvers and Querying respectively!
How do I setup a sensor so that I can run something else after a resolver run?
If you are triggering a resolver run as part of an orchestrated pipeline, we usually see customers using the built-in sensors from the orchestrators (e.g. Airflow or Dagster) to poll for resolver completion. You can also customize this polling using an API to query run status. See here for an example of how to set up Airflow orchestration to trigger and poll a resolver run.
Roadmap
What have the people at Chalk been working on?
To get a glimpse of recently released features, take a look at our changelog!
I want to request a feature!
Feel free to reach out to us with feature requests or questions about feature requests in your support channel!